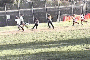|
|
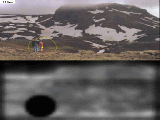
In the first short MPEG video, we show both the original input image and the corresponding saliency map in dynamical evolution. The saliency map begins with charging up from the input. Then the most salient location is found and transiently inhibited. The yellow circle on top of the original image represents the current focus of attention. The first image shows simple objects in noise; objects are selected by order of decreasing saliency (here luminance contrast). After all objects have been attended, less salient locations in the background noise are attended. The previously attended and inhibited locations progressively charge-up again and may be again attended. Then, in the examples of pop-out tasks, the target is the first attended object, independently of the number of distractors. In the example of conjuctive search task however, because the color and orientation features are competing, the target does not pop-out any more (true for humans as well as for the model, which perform a serial search). The BatmanTM poster demonstrates how, generally, the attentional trajectories generated by the model seem to agree with our reading of the image. Note how a good coverage of the image is obtained (attention does not only go to the 3 faces, but looks around about everywhere), with frequent checking on the most salient objects. Good performance was also obtained with a database of traffic sign images from Daimler Benz, Inc. Since road signs have been designed to be salient (the car is also salient here), they are found before the system looks around in the trees. We conclude this demonstration with an example of robustness to noise. |
|
|
In this second video, the spatial competition among conspicuous locations within each feature map is demonstrated. Details about the implementation of such spatial competition can be found in our 2001 Journal of Electronic Imaging paper. |
|
|
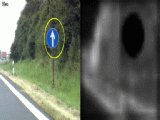
In this third video, performance of the model at detecting traffic signs is demonstrated. No particular tuning of the model was done; all paremeters are set to their default values, and the model is only looking for salient objects with no knowledge that these should be traffic signs. |
|
|
In these fourth and fifth videos, the original image is warped onto the evolving saliency map (an operation which takes no more than a few lines of C++ code). |
|
|
In this sixth video, the generic model is looking at a sequence of frames, and the most salient location is plotted for each frame (on a couple of frames, you will see that two locations were equally salient). So far, there is no temporal processing in the model, and frames are treated independently of each other. In this sequence however, the model seems to reasonably pick-up salient pedestrians getting in the way of the vehicle from which the sequence was filmed, as well as other salient objects such as street markings, tail-lights and street lights. The original video sequence was given to us by Constantine Papageorgiou and Tommy Poggio at MIT-CBCL. |
|
|
In these seventh and eighth videos, a magazine cover submitted to us by Peter Walker, Director of the Neural Nets Group at McCann-Erickson, is evaluated by the full-blown model, which includes non-classical surround inhibition as well as tuned, orientation-specific long-range excitatory connections. |
|
|
Some more evaluations of advertising designs submitted to us by Piers Walker of Advanced Marketing Sciences. |
|
|
This ninth video demonstrates the generality of the model, by evaluating 36 images of natural scenes ranging from beachfront to outer space. The model is able to cope with such variation in its inputs, and makes sensible predictions in most cases. Thus, this video demonstrates how our approach differs from typical computer vision systems, which are developed with a specific environment and visual target in mind. |
|
|
These clips are a simulation of how the raw inputs to your retina may look like when you inspect a video clip and make eye movements. Also see here for related demos. First, have a look at the clip at top. This is a normal video sequence filmed with a camcorder. In some of our experiments, we recorded eye position from human subjects as they watched this video clip. Now have a look at the second clip. This is the same as the first one, except that each frame has been shifted to the current eye position of a human observer; thus this version shows you the distribution of light intensity that hit the subject's retina as he was making eye movements to explore the clip (assuming a black border around the clip). Interestingly, while the motion of the scene induced by eye movements is obvious and extremely annoying in the second clip, subjects do not perceive the same annoyance when they execute their own eye movements, although the visual input hitting their retinas is essentially the same as what you can see here by maintaining your gaze fixed at the center of the images. The third clip is the same as the second one, except for a slightly wider field of view and grey background. |
Copyright © 2000 by the University of Southern California, iLab and Prof. Laurent Itti