We considered the challenging problem of interpreting the reasoning logic of a neural network decision. We propose a novel framework
to interpret neural networks which extracts relevant class-specific visual concepts and organizes them using structural
concepts graphs based on pairwise concept relationships. By means of knowledge distillation, we show VRX can take a step
towards mimicking the reasoning process of NNs and provide logical, concept-level explanations for final model decisions.
With extensive experiments, we empirically show VRX can meaningfully answer “why” and “why not” questions about the prediction,
providing easy-to-understand insights about the reasoning process. We also show that these insights can potentially provide
guidance on improving NN’s performance.
Below shows a 5 mins brief introduction of our Visual Reasoning eXplaination Framework VRX.
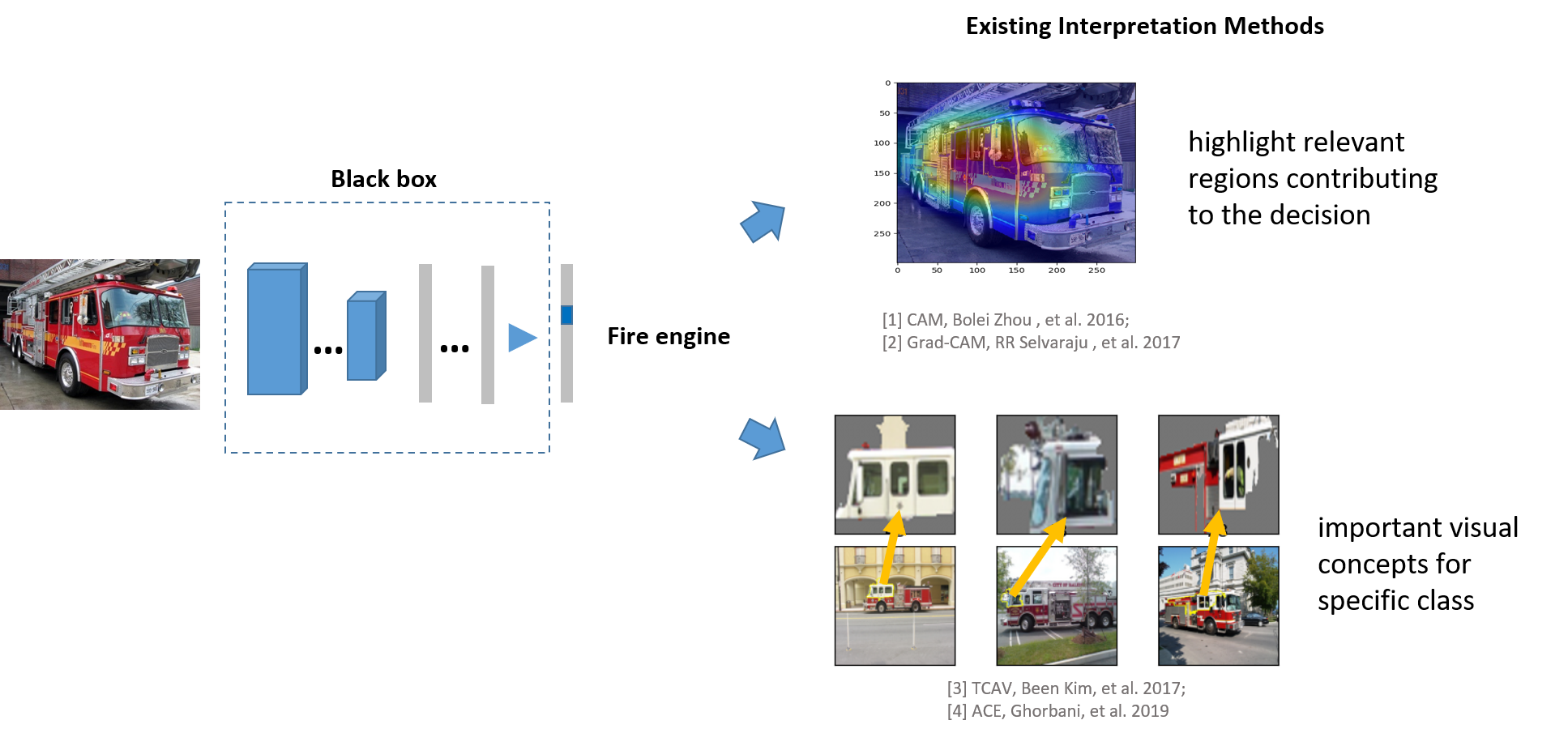
Why we want to do this
For existing methods: (1)Pixel-level interpretation can highlight the relevant regions contributing to the decision.
And (2) Concept level explanations can find the important visual concept for the specific class.
However, they only visualize lower-level correlations between input pixels and prediction – no high-level reasoning (e.g. why class A instead of B)
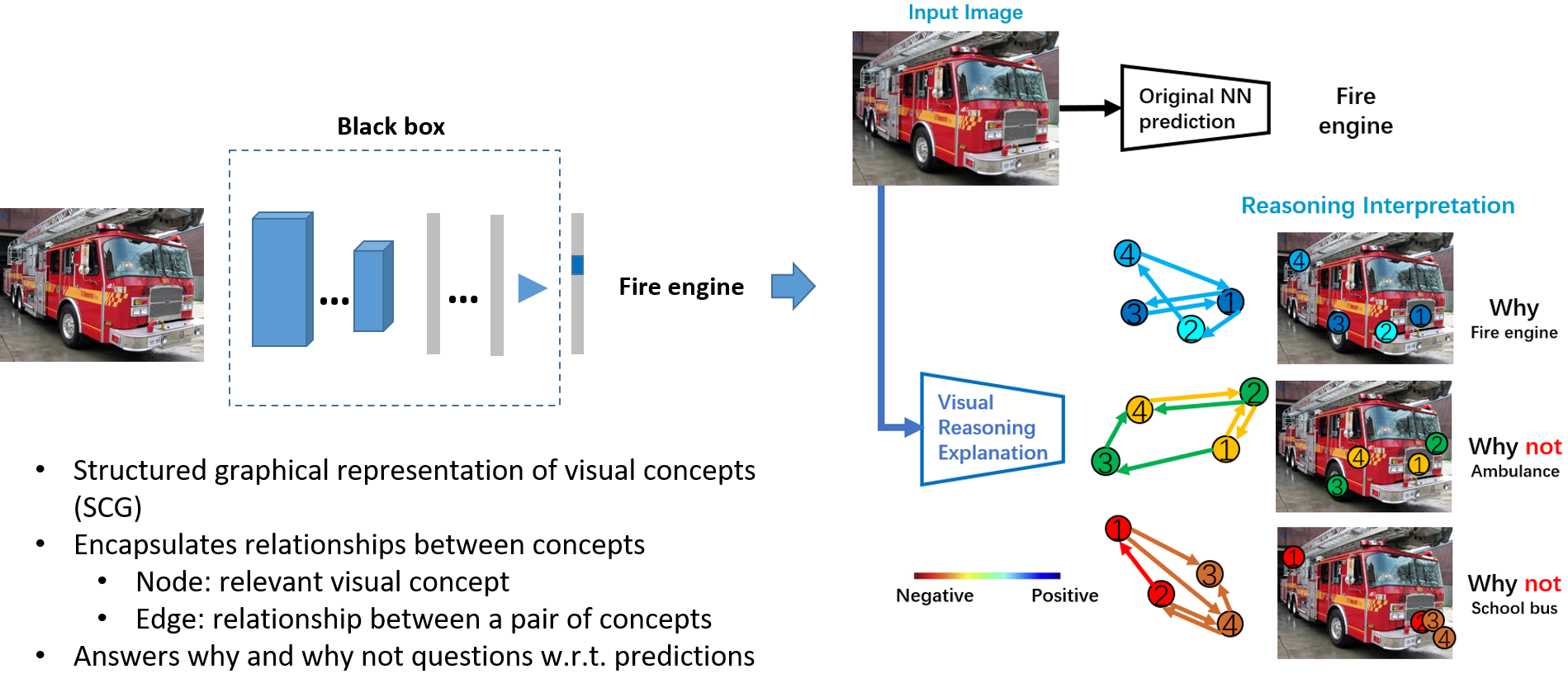
What we have done
Our Visual reasoning explanation takes a step towards mimicking the reasoning process of NNs.
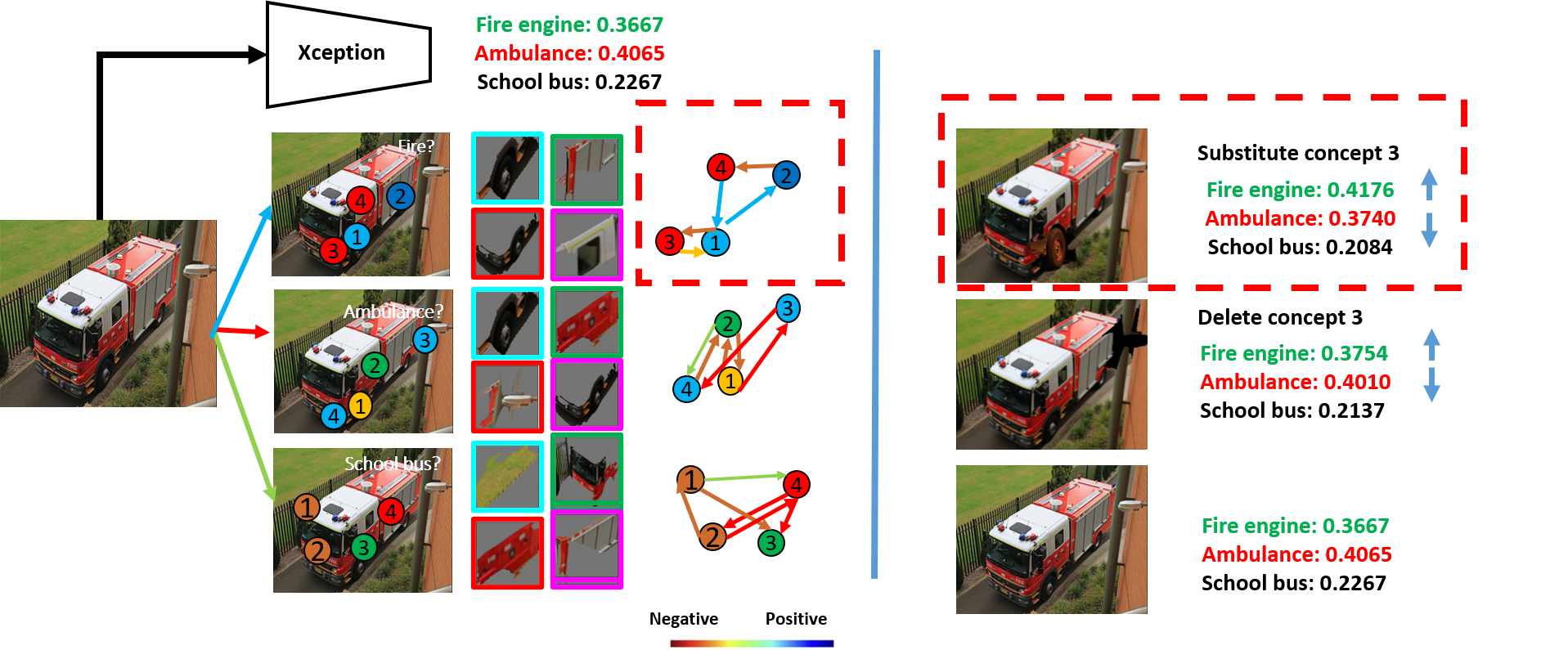
Here we explain this model decision by answer the question: why it is a fire engine?
Why not others? We use the Structural Concept Graph, where nodes represent the visual concepts, edges represent relationships between concepts.
To explain the logic for reasoning, colors of graph nodes and edges represent the positive or negative contribution to the final decision.
Why it is a fire engine? first: all detected 4 fire engine concepts have positive contribution to the fire engine decision, and second: all concept relationships also have positive contribution.
That means both visual concepts and concept relationships look like a fire engine. Why not a school bus? First, the detected concepts, especially concept 1 and 2 and concept relationship have negative contribution to deny the school bus prediction.
we provide logical concept-level explanations.
Methods
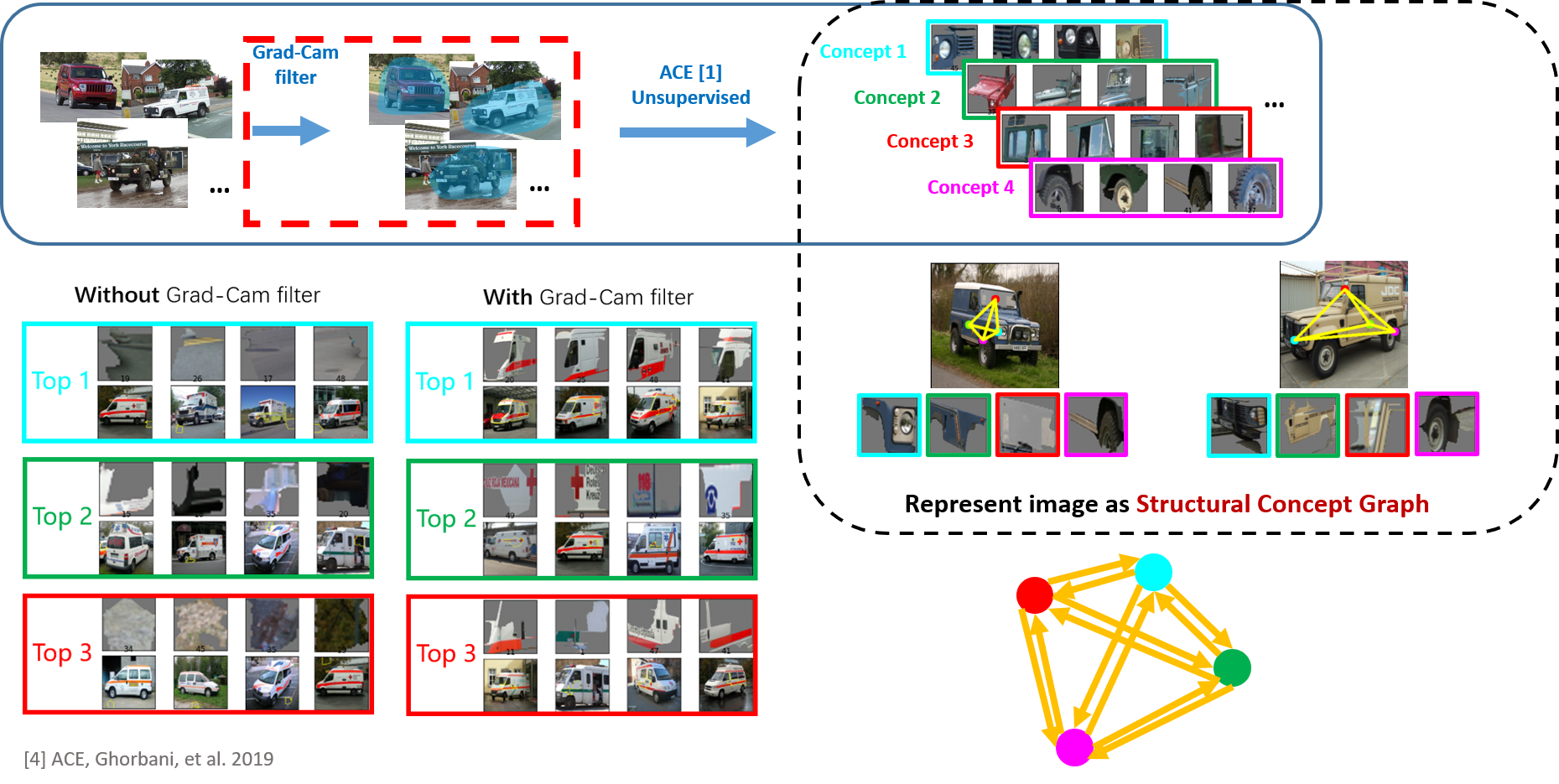
The first step of our method is to extract the class-specific visual concepts.
For instance, to extract jeep concepts, we use Grad-CAM attention map as a filter to mask out the unimportant region for decision and then use an unsupervised method to get the important visual concepts for jeep.
Specifically, adding Grad cam filter can help the extracted concept stay in the foreground which follows causal inference With a detected visual concept, VRX can represent the image as a structural concept graph.
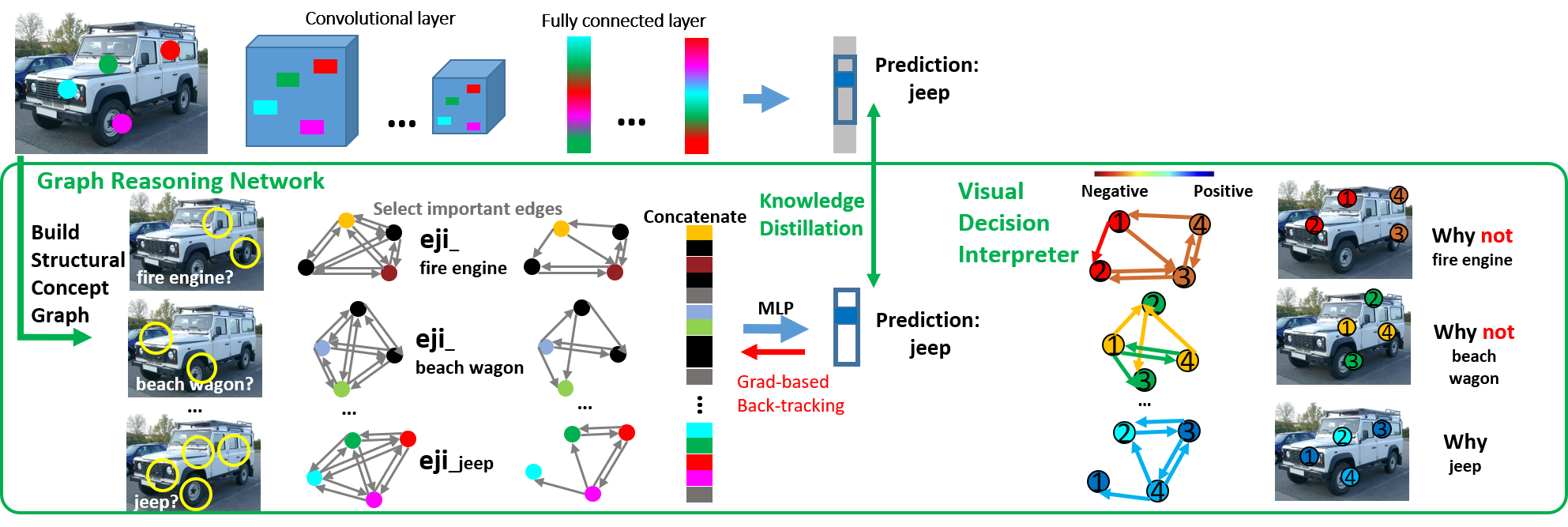
To explain the reasoning process with Structural concept graph, we propose a GNN-based graph reasoning network to mimic the decision of the original NN with knowledge transfer and distillation.
GRN first build structural concept graph for each potential class, then helps optimize the underlying structural relationships between concepts that are important for the original model’s decision. After knowledge transfer, GRN becomes a representation of the original neural network.
During Inference, we propose Gradient-based back-tracking to assign contribution score to each node and edge which means how much contribution does this node or edge help for the final decision. This provide a clear evidence to show the reasoning logic of original model.
Experiments
The first experiment is to verify that the explanation of VRX is logically consistent with the original NN.
When Xception wrongly predicts a fire engine as an ambulance.
VRX can explain the error: it is because the detected fire engine concepts 3 and 4 have negative contribution to correct prediction.
To verify the logic consistency. We substitute the bad concept 3 with a good one from another fire engine image and use Xception to re-predict the class of the modified image,
it corrects the error and predicts correctly. However, if we substitute concept 3 with random patches or substitute the good concept 1 and 2,
Xception can not correct the error, which shows the logic consistency.
The second experiment shows the Interpretation Sensitivity of Appearance and Structures.
We first substitute a relatively good concept patch (with positive contribution score) with a relatively bad concept patch (with negative contribution score),
VRX can precisely locate the modification and give a correct explanation.
Second, when we move one concept’s location from a reasonable place to an abnormal location (like move wheels to the windshield), VRX can precisely capture the abnormal structure and produce a correct explanation.
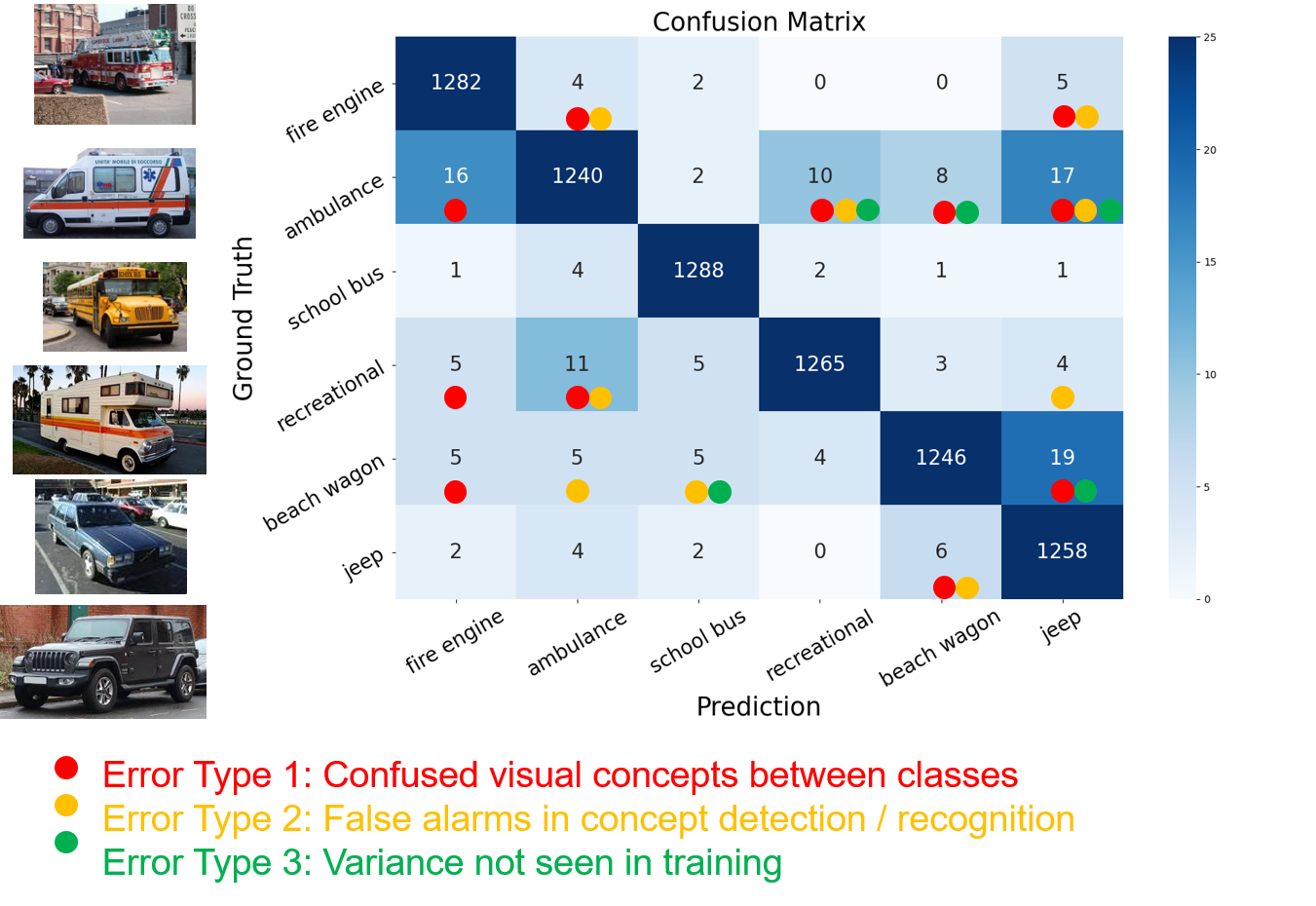
The third experiment shows the VRX can diagnose the original model and guide an improvement of performance.
When we train a model with a pose bias dataset, All buses in pose 1, all military in pose 2, and all tanks in pose 3.
we have bad performance on the unbiased test dataset. VRX use the explanation to diagnose model and find it is the bad concept structure leads to the incorrect prediction,
then provide useful suggestion which improves the original model’s performance.
This experiments shows VRX diagnose an Xception model and categorize 3 main types of errors. Based on explanation, 95% of errors have been correctly explained and automatically corrected by VRX.
Our experiments showed that the VRX can visualize the reasoning process behind neural network’s predictions at the concept level, which is intuitive for human users.
Furthermore, with the interpretation from VRX, we demonstrated that it can provide diagnostic analysis and insights
on the neural network, potentially providing guidance on its
performance improvement. We believe that this is a small
but important step forward towards better transparency and
interpretability for deep neural networks.
Contact / Cite
Got Questions? We would love to answer them! Please reach out by email! You may cite us in your research as:
@inproceedings{ge2021peek,
title={A Peek Into the Reasoning of Neural Networks: Interpreting with Structural Visual Concepts},
author={Ge, Yunhao and Xiao, Yao and Xu, Zhi and Zheng, Meng and Karanam, Srikrishna and Chen, Terrence and Itti, Laurent and Wu, Ziyan},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={2195--2204},
year={2021}
}