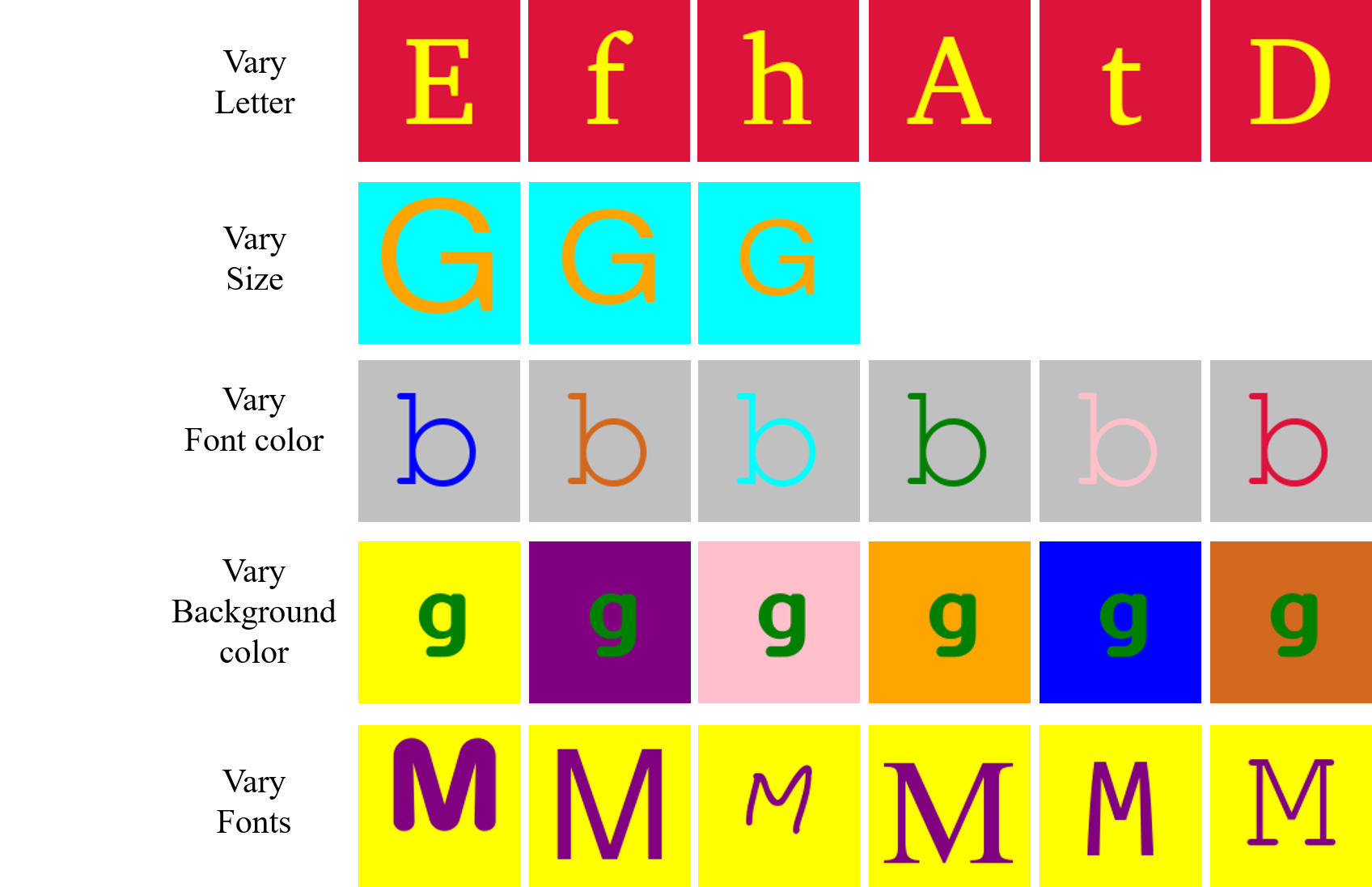
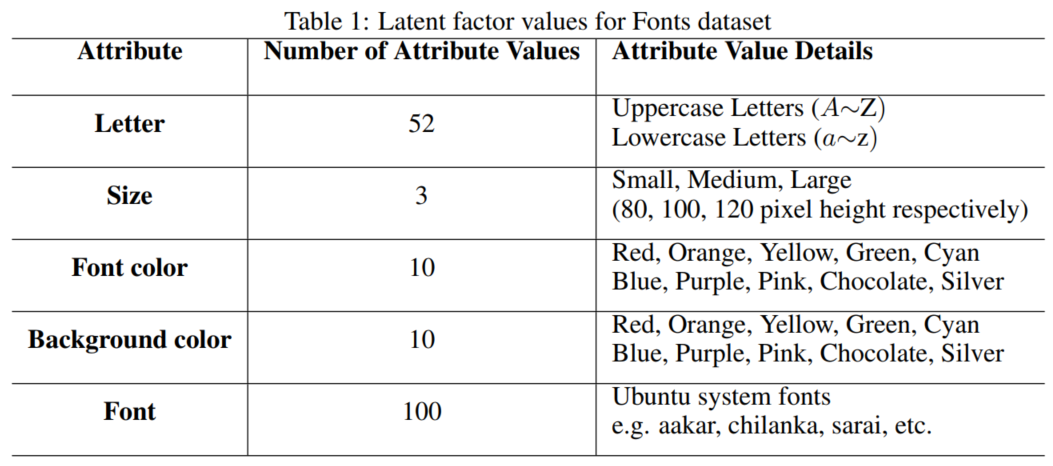
Fonts Dataset
University of Southern California
@inproceedings{ge2021zeroshot,
title={Zero-shot Synthesis with Group-Supervised Learning},
author={Yunhao Ge and Sami Abu-El-Haija and Gan Xin and Laurent Itti},
booktitle={International Conference on Learning Representations},
year={2021},
url={https://openreview.net/forum?id=8wqCDnBmnrT}
}
|
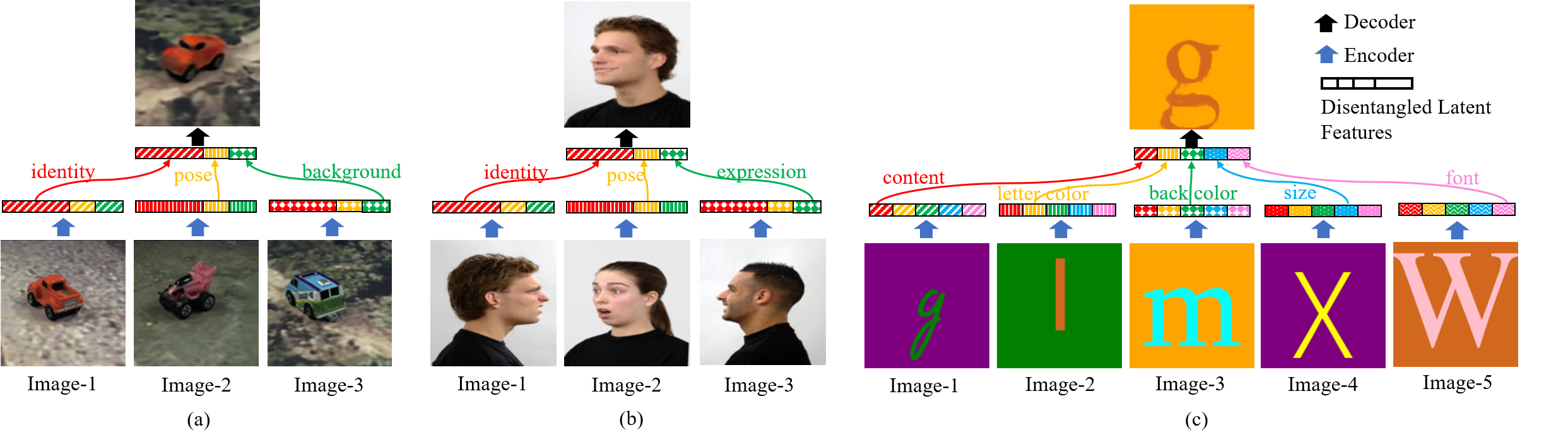
Zero-shot Synthesis with Group-Supervised Learning Yunhao Ge, Sami Abu-El-Haija, Gan Xin and Laurent Itti arXiv:2009.06586, 2020. [Paper] [Code] [Webpage] [Talk Video] [Fonts Dataset] |
Last update: Sep. 14, 2020