
Welcome to our Beowulf page! A Beowulf is a cluster of very cheap Linux machines, hooked up through a local network and using specialized software to work like a very expensive parallel computer. In iLab, we installed in October 2000 a small Beowulf cluster (16 compute nodes) to serve our simulation needs. Below we share our experience with designing, setting up and using the cluster. DesignWe took all the latest hardware of the moment, except that we could not afford the fastest available CPUs. Since any information about that will be obsolete in three months, it's not necessary to dwell on the specific parts. But you can have a look at our facilities page for some details.
A few general comments, though: In our experience, cooling is the key to stability; so we loaded the cluster with a 8cm and a 12cm extra fans in addition to the CPU fan and power supply fan. The 12cm fan was custom-mounted in the front, in the three unused 5-1/4 bays, and pushes air inside the box. The 8cm fan was mounted on the other side of the front panel and also pushes air inside. We have opened 3 slots in the back to allow for air exhaust, since we only have the power supply's fan pulling air out. These openings are diagonally opposite to the 12cm fan, so that the air flow has to go through memory, CPU, chipset and ethernets before it can go out. With that configuration, ambient temperature inside each box is 25C and CPU temperature is 29C.
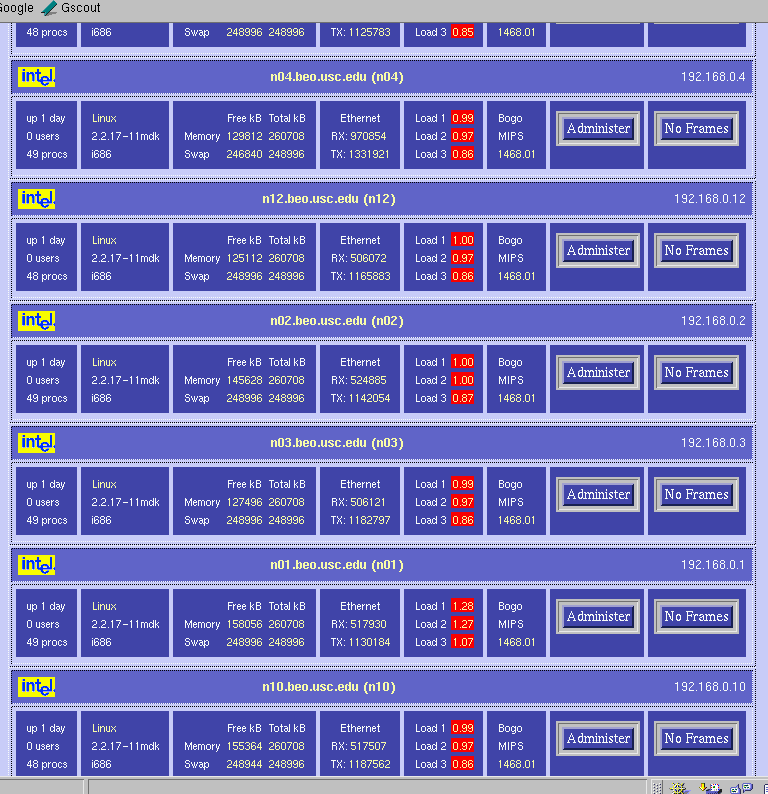
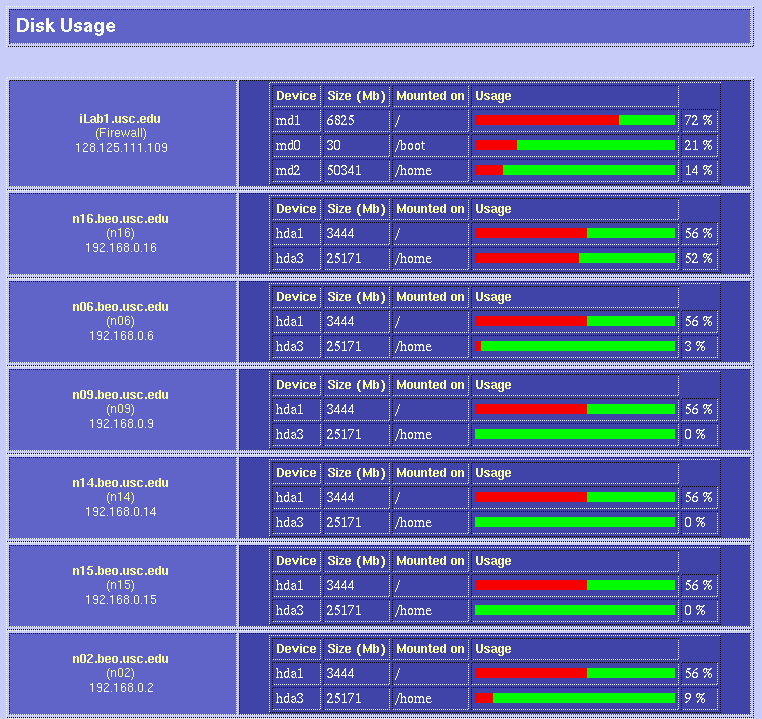
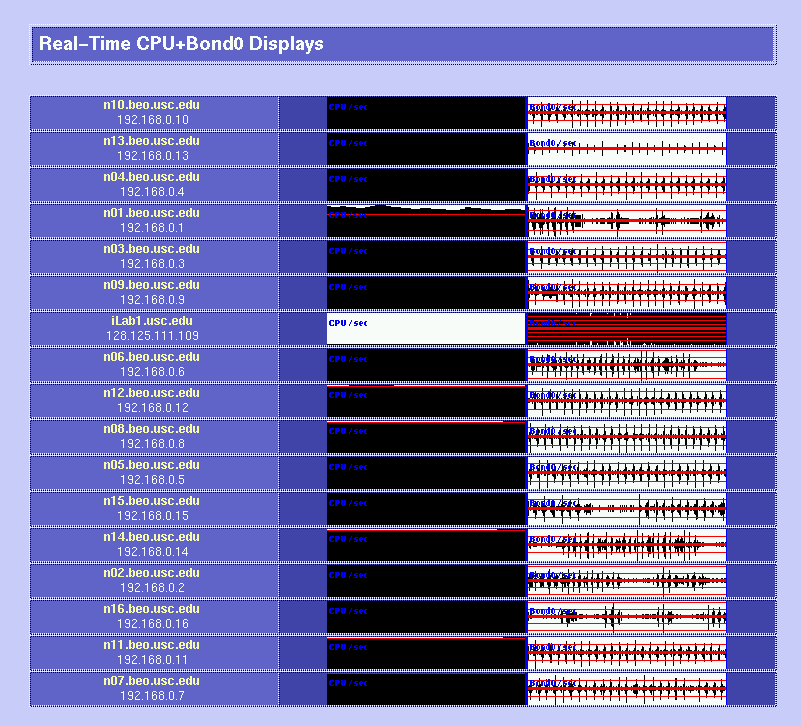
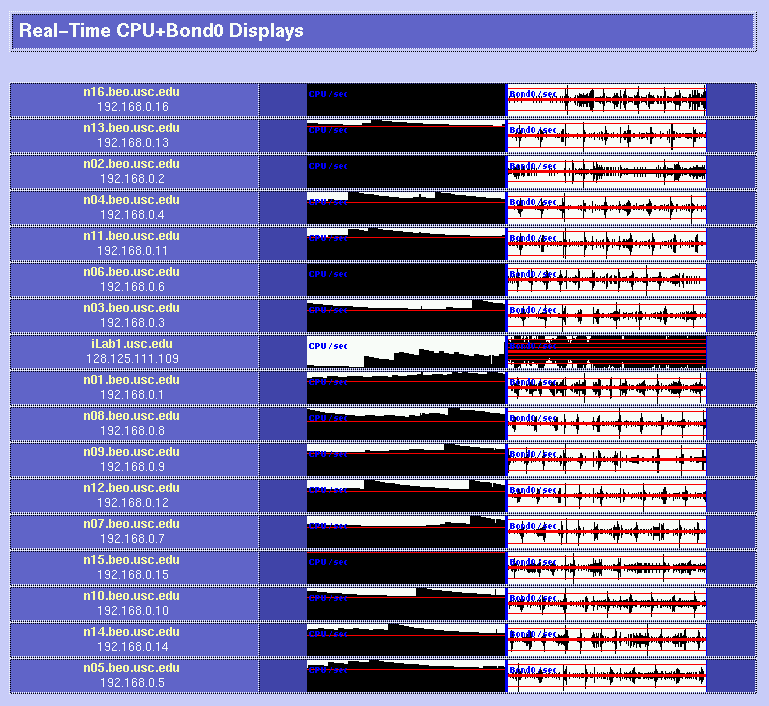
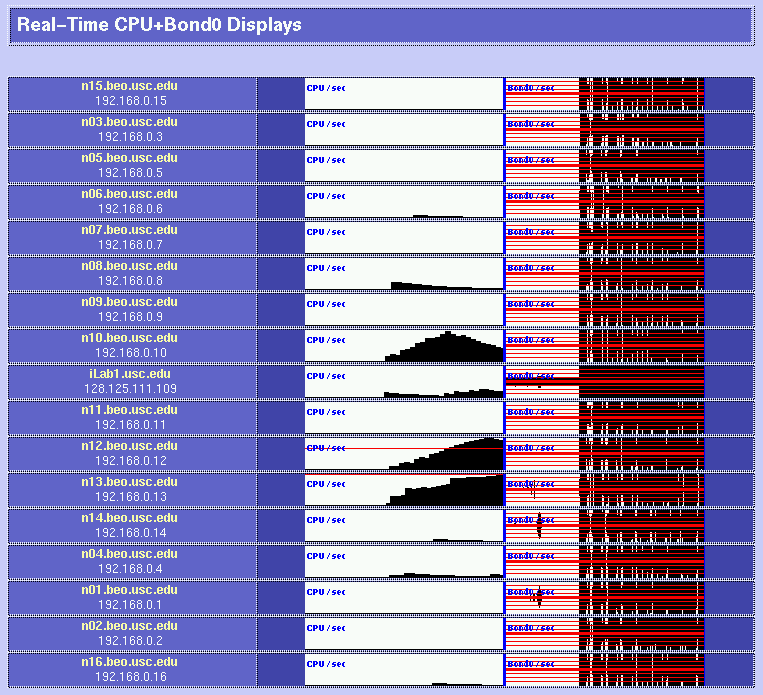
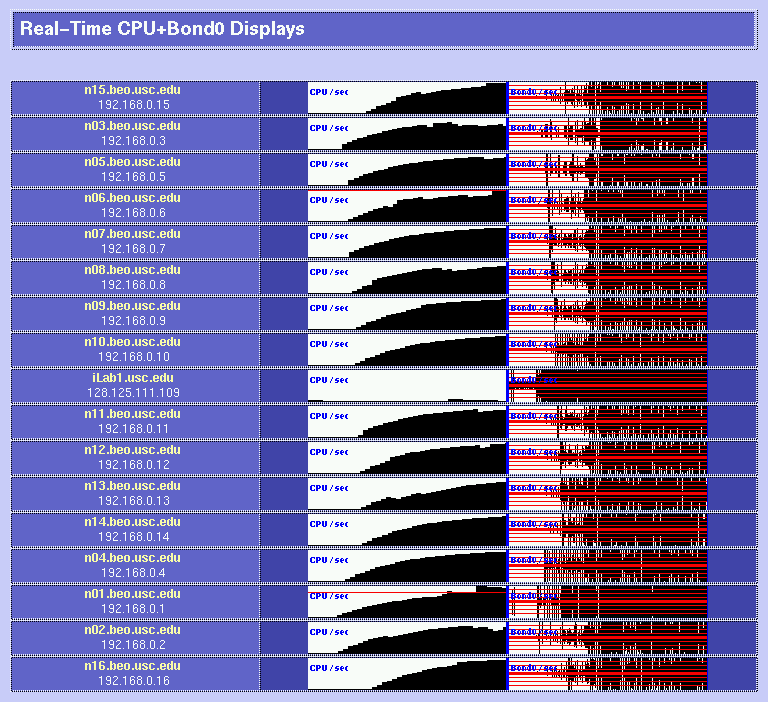
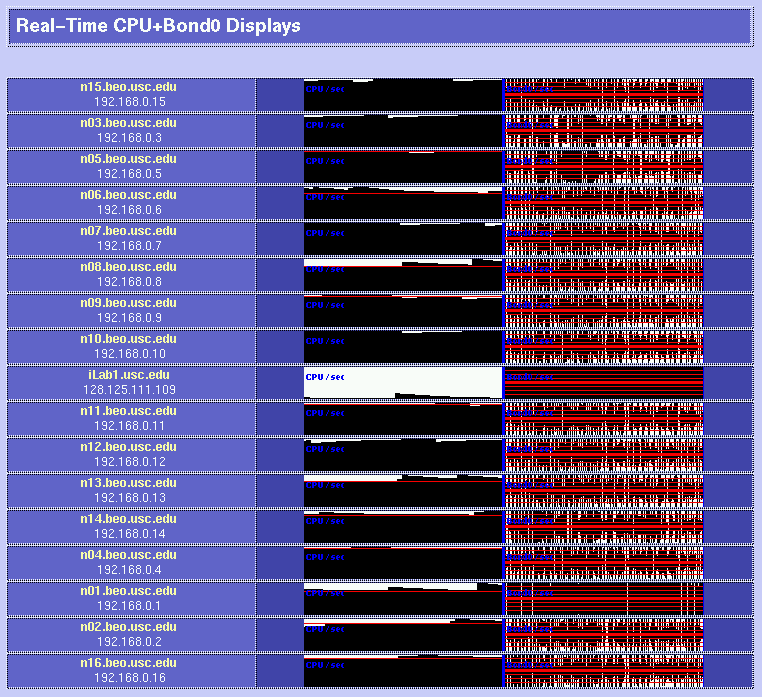
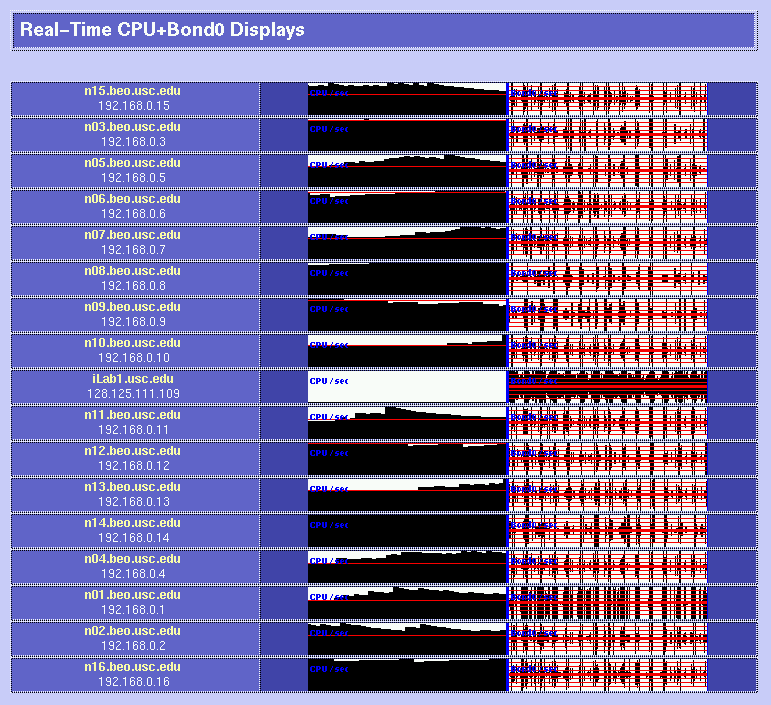
Be very careful when you choose your parts; each hardware operation on a Beowulf will require several hours of hard work (and definitely include an electric screwdriver in your part list!) It may be a good idea to order one box first to see whether everything is okay. If you plan to have add-on boards like we did (three ethernets per box), make sure that you read the motherboard's documentation before giving assembly instructions to your manufacturer: some of the PCI slots on your motherboard are likely to share interrupts, resulting in slightly degraded performance. 3x100Mbps Channel-Bonded NetworkIn order to be able to process video sequences in real-time with our system, we need a very fast network. So we decided to try an extremely cheap solution: triple-ethernet channel bonding. Channel bonding is a Linux feature which allows you to use multiple network cards as if they were one: traffic is simply load-balanced over the multiple devices. You do need to have one separate switch per branch in your network, as it is critical for bonding to work that all the boards in one machine have the same MAC (ethernet) address (and that would confuse a single switch, since it would not know to which port it should send a packet destined to a given MAC address). We installed three RealTek RTL8139 ($7.60 each) boards in each node, and connected them through three very cheap switches ($260 each). As mentioned before, be careful about the PCI slots in which you place your boards if you want each to have its own interrupt; placing them in PCI slots 1, 2 and 3 worked for us (rather than nicely interleaving them into slots 1, 3 and 5 as we had originally to maximize cooling). It seems that changing the MAC address when you bring up the bonded channel does not work with the RTL8139 chips (even though it looks like it worked as per ifconfig; but using rtl8139-diag from Donald Becker showed that the eeprom had not been modified to the new MAC address (when you bring the bond up, it tries to copy the MAC address of the first enslaved device to the other devices). So we decided to just create our own MAC addresses (since we are on a local net) and to permanently burn them into the eeproms. For that, we had to add a few lines of code to rtl8139-diag, and the modified program with eeprom-write capability is here. This done, everything worked great! The bonding kernel module was already included in our Mandrake 7.2beta3 GNU/Linux distribution, so it was just a matter of configuring the various ifcfg-eth* and we were set. How about actual performance? Here are some test results using NetPerf, under normal use conditions (multi-user runlevel, many processes running, boxes hooked up through the switches): TCP transfer rates between two nodes:[root@n01 /root]# netperf -l 60 -H n11 TCP STREAM TEST to n11 Recv Send Send Socket Socket Message Elapsed Size Size Size Time Throughput bytes bytes bytes secs. 10^6bits/sec 65535 65535 65535 60.00 244.06 UDP transfer rates between two nodes:[root@n01 /root]# netperf -H n11 -t UDP_STREAM -- -m 10240 UDP UNIDIRECTIONAL SEND TEST to n11 Socket Message Elapsed Messages Size Size Time Okay Errors Throughput bytes bytes secs # # 10^6bits/sec 65535 10240 9.99 32503 0 266.49 65535 9.99 32319 264.98 A single board can get up to 94 Mbps throughput, so it does not perfectly scale up when using 3 boards, but for about $60 per node (including boards, switches and enhanced CAT5 cables), we are fully satisfied with the performance! BRAIN-1 in action!Here are a few examples of the cluster in action. In these examples, we process 9600 images with our model of bottom-up visual attention. We wrote a perl script to spread the work over the 16 compute nodes (n01 through n16) while having some progress displays on the console (iLab1).
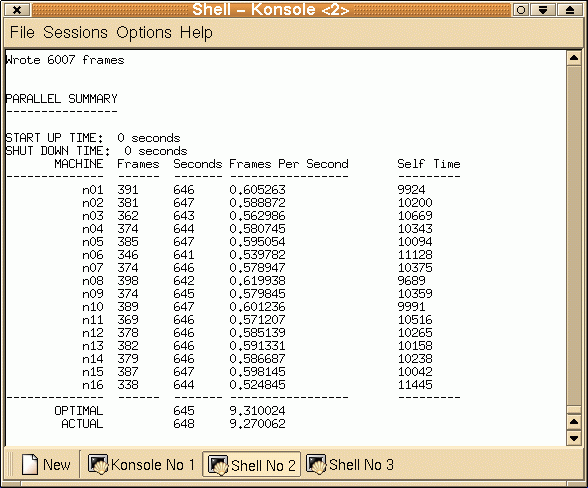
Parallel processing of visual saliencyHere is a first implementation of our bottom-up, saliency-based visual attention algorithm for real-time operation. It all works at 15 frames/sec, including video grabbing, processing, and display. Have a look! See our Ongoing Projects for more details. Parallel encoding of mpeg moviesThe parallel version of mpeg_encode works great too. Check out the Beowulf at work on a 6,000-frame movie and some processing statistics. Copyright © 2000 by the University of Southern California, iLab and Prof. Laurent Itti |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}