
This is a simple demonstration which we put together with robotics experts from Stefan Schaal's laboratory for the Robot Exposition and Open House at the National Science Foundation on September 16, 2005. Zach Gossman, an undergraduate student at iLab, wrote the code for this demo. A stripped-down version of our saliency-based visual attention code runs in real-time on a portable workstation with a single dual-core processor. Video inputs are digitized from cameras in the eyes of the robot and processed at 30 frames/s. Saliency maps are computed, highlighting in real-time which locations in the robot's surroundings would most strongly attract the attention of a typical human observer. At any given time, the coordinates of the most active locations are then transmitted to the robot head's motor control system, which then executes a combination of rapid (saccadic) eye movements and slower (smooth pursuit) eye and head movements. |  |
 | We have developed a new method for automatically finding regions of interest in static images or video clips, using a neurobiological model of visual attention. This model computes a topographic saliency map which indicates how conspicuous every location in the input image is, based on the responses from simulated neurons in primary visual cortex, sensitive to color, intensity, oriented edges, flicker and oriented motion. The method is applied as a front-end filter for image and video compression, where a spatially-variable blur is applied to the input images prior to compression. Image locations determined interesting (or salient) by the attention model receive no or little blur, while image locations increasingly farther from those hot spots are increasingly blurred. Locations which are more highly blurred will be compressed more efficiently and hence will yield a smaller overall compressed file size. To the extent that the algorithm indeed automatically marked as hot spots regions that human observers would find interesting, the blur around those regions should be tolerable when viewing the resulting clips. Details may be found on our Saliency-based Video Compression page. Papers describing the results have appeared in the IEEE Seventh International Symposium on Signal Processing and its Applications, the SPIE conference on Human Vision and Electronic Imaging, and the IEEE Transactions on Image Processing. |
We are exploring the uses of our bottom-up visual attention algorithm in the guidance of an autonomous vehicle with a small video camera as its only sensor. Currently, the vehicle is radio-controlled, and video is sent to our 16-CPU Beowulf cluster through a 2.4GHz wireless link. This vehicle is the smallest off-road toy vehicle we could find, about 10cm in overall length (the diameter of the camera module mounted on top is just slightly larger than a US quarter dollar coin. Watch its first exploratory trip around the building in this MPEG movie (7.3MB) and note how it easily finds all interesting landmarks even though the blue channel was lost during this recording, hence the yellowish aspect of the movie. (Make sure you use a fast player - the time counter in the top-left corner should increment by 5ms steps when no frames are dropped). After successful trials using the small radio-controlled car shown here, we have decided to start a larger-scale project, the Beobot Project. | 
|
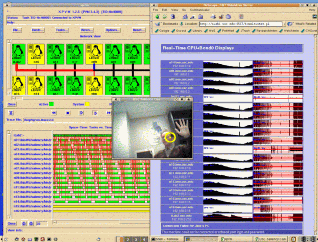 | We are developing a parallel implementation of our bottom-up saliency-based attention algorithm. The first prototype implementation ran at 15 frames/s for 320x240 resolution on our 16-CPU Beowulf cluster. It used PVM (Parallel Virtual Machine, from Oak Ridge National Laboratory) to spread processing across the CPUs linked by our channel-bonded 3x100Mbps network. And it worked! But we wanted to go faster. So we developed our own direct TCP transport library in C++ and now achieve real-life transfer rates >205Mbps (PVM transfers at 30Mbps over our 3x100Mbps network, almost a 10-fold slowdown). Check out the current implementation (6 MB mpeg), which runs at a full 30 frames/s with a latency of just 2 frames (i.e., each frame is fully processed over the Beowulf in 60ms). For this demo we have disabled the inhibition-of-return, so the the model just keeps focusing on the most salient object in the scene, rather than scanning the scene in order of decreasing saliency. Currently, the CPU and net loads are very low with the algorithm running at 320x240 @ 30 fps, so we have a lot of room on our Beowulf to grow the algorithms! Check out this new movie (12 MB MPEG) that includes a channel sensitive to flicker (also see below), and allows the algorithm to pickup salient moving objects, while remaining largely insensitive to camera motion (notice how the most salient location remains quite stable when the camera is jerked around). In this movie also, inhibition-of-return was disabled, so that the system keeps focusing on the most salient location in the visual field, rather than quickly scanning several locations in order of decreasing saliency. |
In this study, we combine our saliency-based bottom-up attention model with the HMAX model of object recognition from Riesenhuber and Poggio at MIT. Our attention system determines interesting locations, and feeds only a small cropped region of the image around those locations to the recognition module. The recognition module then determines whether there is a pedestrian in the image region it received. Our preliminary results indicate that combining those two neuromorphic vision models, one concerned with localization of targets and the other with their identification, may yield a very powerful scene analysis model. Florence Miau obtained some very interesting preliminary results on this project, as described in her IEEE EMBS paper and her SPIE paper. | 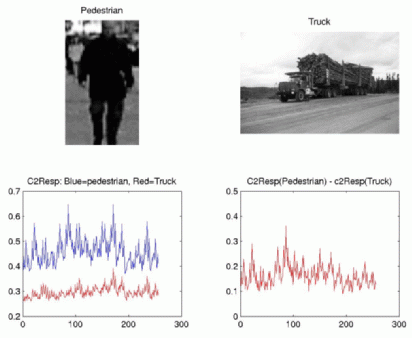
|
 | In addition to real-time parallel implementation issues, computing saliency in animated sequences poses a number of computational challenges: Extraction of motion-based salient cues, object-based inhibition-of-return, and ensuring a smooth temporal continuity in the saliency map. We have some preliminary results where long-term stability of the saliency map seems to have been achieved through a number of new self-regulation mechanisms. Check out this MPEG movie (2.5MB) of the sequence from Tommy Poggio (MIT) and Daimler Benz. (Make sure you use a fast player - the time counter in the top-left corner should increment by 5ms steps when no frames are dropped). Contrary to the processing of that same sequence in our movie page, this new one now remembers recently attended locations across frames. Also check this new movie (31MB), which includes a new processing channel sensitive to flicker in the intensity modality. |
Copyright © 2001 by the University of Southern California, iLab and Prof. Laurent Itti
{kind=link}