
We are developing a trainable model of bottom-up, task-independent,
saliency-based selective visual attention. It is based on the
original idea first advanced by Koch and Ullman (
This project was started as part of the ONR Multidisciplinary University Research Initiative (MURI) involving the M.I.T., Harvard University and Caltech from 1995 to 2000.
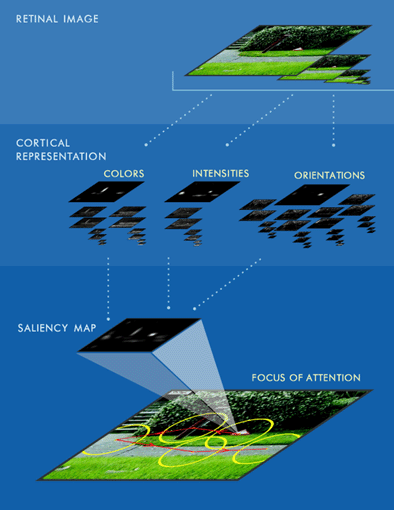
We here present a brief overview of our model for the bottom-up control of visual attention in primates. Given an input image, this systems attempts to predict which location in the image will automatically and inconsciously your attention towards them
In this biologically-inspired system, an input image is decomposed into a set of multiscale neural ``feature maps'' which extract local spatial discontinuities in the modalities of color, intensity and orientation. Each feature map is endowed with non-linear spatially competitive dynamics, so that the response of a neuron at a given location in a map is modulated by the activity in neighboring neurons. Such contextual modulation, also inspired from recent neurobiological findings, has proven remarkably efficient at extracting salient targets from cluttered backgrounds. All feature maps are then combined into a unique scalar ``saliency map'' which encodes for the salience of a location in the scene irrespectively of the particular feature which detected this location as conspicuous. A winner-take-all neural network then detects the point of highest salience in the map at any given time, and draws the focus of attention towards this location. In order to allow the focus of attention to shift to the next most salient target, the currently attended target is transiently inhibited in the saliency map (a mechanism, ``inhibition-of-return'' which has been extensively studied in human psychophysics). The interplay between winner-take-all and inhibition-of-return ensures that the saliency map is scanned in order of decreasing saliency by the focus of attention, and generates the model's output in the form of spatio-temporal attentional scanpaths.
Recently, we have applied this model to many different visual tasks using static images, including a number of ATR tasks where we observed remarkable model performance at picking out salient targets from cluttered environments. These include the reproduction by the model of human behavior in classical visual search tasks (pop-out versus conjunctive search, and search asymmetries); a demonstration of very strong robustness of the salience computation with respect to image noise; the automatic detection of traffic signs and other salient objects in natural environment; the detection of pedestrians in natural scenes; the evaluation of advertizing designs; and the detection of military vehicles in cluttered rural environments.
The model is developed in accordance with the known anatomy and physiology of the visual system of the macaque monkey. It comprises two interacting stages:
The link between the two stages is a Saliency Map, which topographically encodes for the local conspicuity in the visual scene, and controls where the focus of attention is currently deployed. The saliency map directly receives its inputs from the preattentive, parallel feature extraction stage. Supervised learning can be introduced to bias the relative weights of the features in the construction of the saliency map and achieve some degree of specialization towards target detection tasks.
The original architecture (Itti, Koch & Niebur, IEEE PAMI, 1998) shown below:
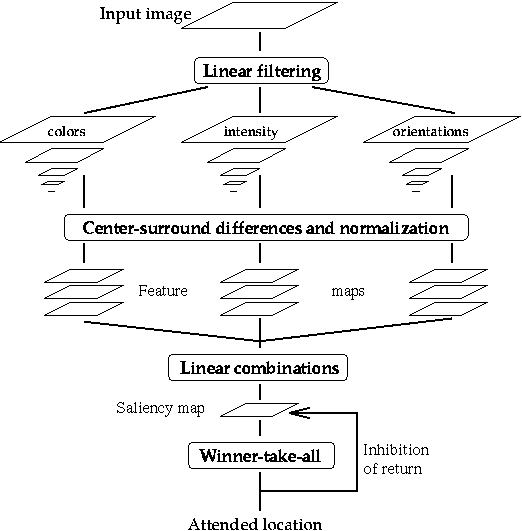
has since then been extended in many directions, including to include eye and head movement animation, as discussed in Itti, Dhavale & Pighin, Proc. SPIE, 2003 and summarized below:
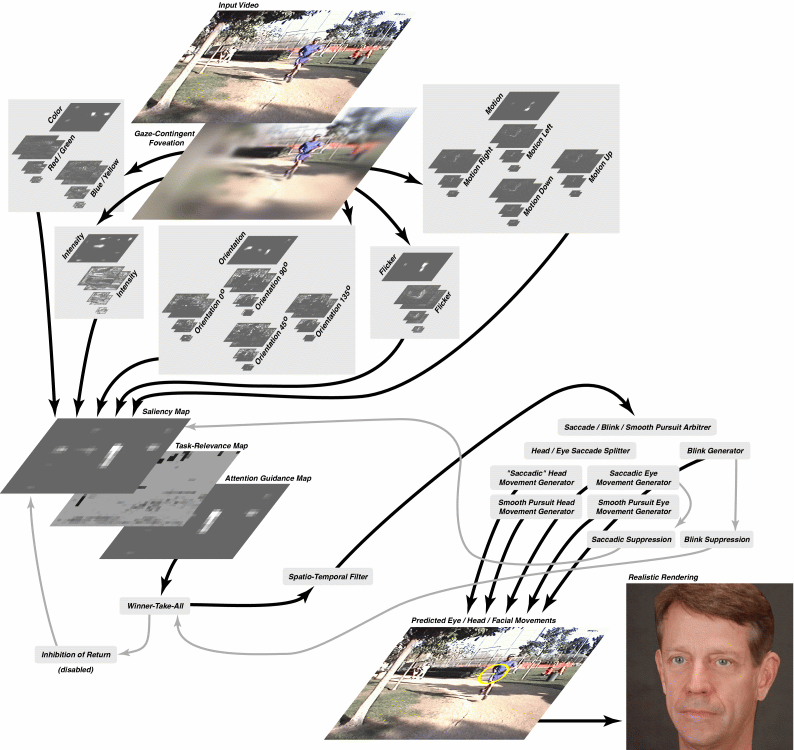
and also to include modulation by top-down task demands, as discussed in Navalpakkam & Itti, Vision Research, 2005 and summarized below:
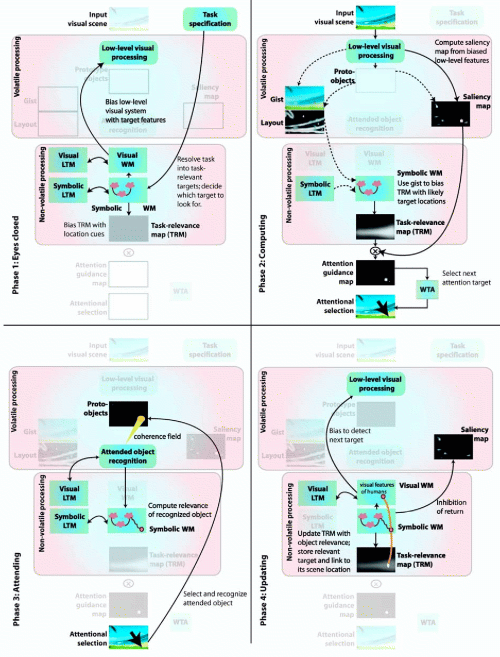
Copyright © 2000 by the University of Southern California, iLab and Prof. Laurent Itti