
Gist/Context of a Scene
We describe and validate a simple context-based scene recognition
algorithm using a multiscale set of early-visual features, which
capture the “gist” of the scene into a low-dimensional signature
vector. Distinct from previous approaches, the algorithm presents
the advantage of being biologically plausible and of having low
computational complexity, sharing its low-level features with a model
for visual attention that may operate concurrently on a vision system.
We compare classification accuracy using scenes filmed at three
outdoor sites on campus (13,965 to 34,711 frames per site). Dividing
each site into nine segments, we obtain segment classification rates
between 84.21% and 88.62%. Combining scenes from all sites (75,073
frames in total) yields 86.45% correct classification, demonstrating
generalization and scalability of the approach.
Index Terms: Gist of a scene, saliency, scene recognition,
computational neuroscience, image classification, image statistics,
robot vision, robot localization.
Papers
-
Main paper for model details:


 C. Siagian, L. Itti,
Rapid Biologically-Inspired Scene
Classification Using Features Shared with Visual
Attention,
C. Siagian, L. Itti,
Rapid Biologically-Inspired Scene
Classification Using Features Shared with Visual
Attention,
IEEE Transactions on Pattern Analysis and Machine Intelligence,
Vol. 29, No. 2, pp. 300-312, Feb 2007.
-
Comparison with 3 other gist models (Renniger and Malik [2004vr],
Oliva and Torralba [2001ijcv], and Torralba et. al. [2003iccv]):
C. Siagian, L. Itti,
Comparison of gist models in rapid scene categorization tasks,
In: Proc. Vision Science Society Annual Meeting (VSS08),
May 2008.
Source Codes and Dataset
The code is integrated to
the iLab Neuromorphic Vision
C++ Toolkit. In order to gain code access, please follow the
download instructions there.
Special instruction to access the
gist code can be found
here.
The dataset can be found here.
Introduction
Significant number of mobile-robotics approaches addresses this
fundamental problem by utilizing sonar, laser, or other range sensors
[Fox1999,Thrun1998a]. They are particularly effective indoors due to
many spatial and structural regularities such as flat walls and narrow
corridors. In the outdoors, however, these sensors become less robust
given all the protrusions and surface irregularities
[Lingemann2004]. For example, a slight change in pose can result in
large jumps in range reading because of tree trunks, moving branches,
and leaves.
These difficulties with traditional robot sensors have prompted
research towards vision. Within Computer Vision, lighting (especially
in the outdoors), dynamic backgrounds, and view-invariant matching
become major hurdles to overcome.
Object-based approaches [Abe1999,Thrun1998b] recognize physical
locations by identifying sets of pre-determined landmark objects (and
their configuration) known to be present at a location. This typically
involves intermediate steps such as segmentation, feature grouping,
and object recognition. Such layered approach is prone to carrying
over and amplifying low-level errors along the stream of
processing.
It should also be pointed out that this approach may
be environment-specific in that the objects are hand-picked as
selecting reliable landmarks is an open problem.
Region-based approaches [Katsura2003,Matsumoto2000, Murrieta-Cid2002]
uses segmented image regions and their relationships to form a
signature of a location. This requires robust segmentation of
individual regions, which is hard for unconstrained environment such
as a park where vegetation dominates.
Context-based approaches ([Renniger and Malik 2004],[Ulrich and
Nourbakhsh 2000],[Oliva and Torralba 2001],[Torralba 2003]), on the
other hand, bypass the above traditional processing steps and consider
the input image as a whole and extract a low-dimensional signature
that summarizes the image's statistics and/or semantics. One
motivation for such approach is that it is more robust solutions
because random noise, which may catastrophically influence local
processing, tends to average out globally.
Despite recent advances in computer vision and robotics, humans still
perform orders of magnitude better in outdoors localization and
navigation than the best available systems. And thus, it is inspiring
to examine the low-level mechanisms as well as the system-level
computational architecture according to which human vision is
organized (figure 1).
Figure 1. Biological Vision Model
Early on, the human visual processing system already makes decisions
to focus attention and processing resources onto small regions which
look more interesting. The mechanism by which very rapid holistic
image analysis gives rise to a small set of candidate salient
locations in a scene has recently been the subject of comprehensive
research efforts and is fairly well understood [Treisman_Gelade80,
Wolfe94, Itti_etal98, Itti_Koch01].
Parallel with attention guidance and mechanisms for saliency
computation, humans demonstrate ability in capturing the "gist" of a
scene; for example, following presentation of a photograph for just a
fraction of a second, an observer may report that it is an indoor
kitchen scene with numerous colorful objects on the countertop
[Potter1975,Biederman82,Tversky1983,Oliva1997]. Such report at a
first glance (brief exposures of 100ms or below) onto an image is
remarkable considering that it summarizes the quintessential
characteristics of an image, a process previously expected to require
much analysis such as general semantic attributes (e.g., indoors,
outdoors, office, kitchen), recognition of places with a restricted
spatial layout [Epstein_Kanwisher00] and a coarse evaluation of
distributions of visual features (e.g., highly colorful, grayscale,
several large masses, many small objects)
[Sanocki_Epstein97,Rensink00].
The idea that saliency and gist runs in parallel is further
strengthened in a psychophysics experiment that humans can answer
specific questions even when the subject's attention is simultaneously
engaged by another concurrent visual discrimination task
[Li_etal02]. From the point of view of desired results, gist and
saliency appear to be complementary opposites: finding salient
locations requires finding those image regions which stand out by
significantly differing from their neighbors, while computing gist
involves accumulating image statistics over the entire scene. Yet,
despite these differences, there is only one visual cortex in the
primate brain, which must serve both saliency and gist computations.
Part of our contribution is to make the connection between these two
crucial components of biological mid-level vision. To this end, we
here explicitly explore whether it is possible to devise a working
system where the low-level feature extraction mechanisms - coarsely
corresponding to cortical visual areas V1 through V4 and MT - are
shared as opposed to computed separately by two different machine
vision modules. The divergence comes at a later stage, in how the
low-level vision features are further processed before being
utilized. In our neural simulation of posterior parietal cortex along
the dorsal or ``where'' stream of visual processing
[Ungerleider_Mishkin82], a saliency map is built through spatial
competition of low-level feature responses throughout the visual
field. This competition quiets down locations which may initially
yield strong local feature responses but resemble their neighbors,
while amplifying locations which have distinctive appearances. In
contrast, in our neural simulation of inferior temporal or the
``what'' stream of visual processing, responses from the low-level
feature detectors are combined to produce the gist vector as a
holistic low-dimensional signature of the entire input image. The two
models, when run in parallel, can help each other and provide a more
complete description of the scene in question.
While exploitation of the saliency map has been extensively described
previously for a number of vision tasks
[Itti_etal98pami,Itti_Koch00vr,Itti_Koch01nrn,Itti04tip], we describe
how our algorithm compute gist in an inexpensive manner by using the
same low-level visual front-end as the saliency model. In what
follows, we use the term gist in a more specific sense than its broad
psychological definition (what observers can gather from a scene over
a single glance), by formalizing it as a relatively low-dimensional
scene representation which is acquired over very short time frames and
use it to classify scenes as belonging to a given category. We
extensively test the gist model in three challenging outdoor
environments across multiple days and times of days, where the
dominating shadows, vegetation, and other ephemerous phenomena are
expected to defeat landmark-based and region-based approaches. Our
success in achieving reliable performance in each environment is
further generalized by showing that performance does not degrade when
combining all three environments. These results support our hypothesis
that gist can reliably be extracted at very low computational cost,
using very simple visual features shared with an attention system in
an overall biologically-correct framework.
Design and Implementation
The core of our present research focuses on the process of extracting
the gist of an image using features from several domains, calculating
its holistic characteristics but still taking into account coarse
spatial information. The starting point for the proposed new model is
the existing saliency model of Itti et al. [Itti_etal98pami], freely
available on the World-Wide-Web.
Please see the iLab Neuromorphic Vision C++ Toolkit for all the source code.
Visual Feature Extraction
In the saliency model, an input image is filtered in a number of
low-level visual feature channels - color, intensity, orientation,
flicker and motion - at multiple spatial scales. Some channels, like
color, orientation, or motion, have several sub-channels, one for each
color type, orientation, or direction of motion. Each sub-channel has
a nine-scale pyramidal representation of filter outputs. Within each
sub-channel, the model performs center-surround operations between
filter output at different scales to produce feature maps. The
different feature maps for each type allows the system to pick up
regions at several scales with the added lighting invariance. The
intensity channel output for the illustration image of figure below
shows different-sized regions being emphasized according to their
respective center-surround parameter.
Figure 2. Gist Model
The saliency model uses feature maps to detect conspicuous regions in
each channel through additional winner-take-all mechanisms to yield a
saliency map which emphasize locations which substantially differ from
their neighbors [Itti_etal98pami]. To re-use the same intermediate
maps for gist as for attention, our gist model uses the already
available orientation, color and intensity channels (flicker and
motion are here assumed to be more dominantly determined by the
robot's egomotion and hence unreliable in forming a gist signature of
a given location). The basic approach is to exploit statistical data
of color and texture measurements in predetermined region
subdivisions.
We incorporate information from the orientation channel, employing
Gabor filters to the greyscale input image at four different angles
and at four spatial scales for a subtotal of sixteen sub-channels. We
do not perform center-surround on the Gabor filter outputs because
these filters already are differential by nature. The color and
intensity channel combine to compose three pairs of color opponents
derived from Ewald Hering's Color Opponency theories [Turner1994],
which identify color channels' red-green and blue-yellow opponency
pairs along with intensity channel's dark-bright opponency. Each of
the opponent pairs are used to construct six center-surround scale
combinations. These eighteen sub-channels along with the sixteen Gabor
combinations add up to a total of thirty-four sub-channels
altogether. Because the present gist model is not specific to any
domain, other channels such as stereo could be used as well.
Gist Feature Extraction
After the center-surround features are computed, each sub-channel
extracts a gist vector from its corresponding feature map. We apply
averaging operations (the simplest neurally-plausible computation) in
a fixed four-by-four grid sub-regions over the map. Observe a
sub-channel in figure below for visualization of the
process. This is in contrast with the winner-take-all competition
operations used to compute saliency; hence, saliency and gist
emphasize two complementary aspects of the data in the feature maps:
saliency focuses on the most salient peaks of activity while gist
estimates overall activation in different image regions.
Figure 3. Gist Extraction
PCA/ICA Dimension Reduction
The total number of raw gist feature dimension is 544, 34 feature maps times 16 regions per
map (figure below). We reduce the dimensions using Principal Component Analysis (PCA) and then
Independent Component Analysis (ICA) with FastICA to a more practical number of 80
while still preserving up to 97% of the variance for a set in the upwards of 30,000 campus
scenes.
Scene Classification
For scene classification, we use a three-layer neural network (with
intermediate layers of 200 and 100 nodes), trained with the
back-propagation algorithm. The complete process is illustrated in
figure 2.
Testing and Results
We test the system using
this dataset.
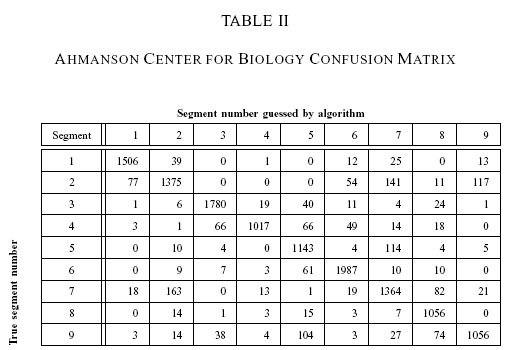
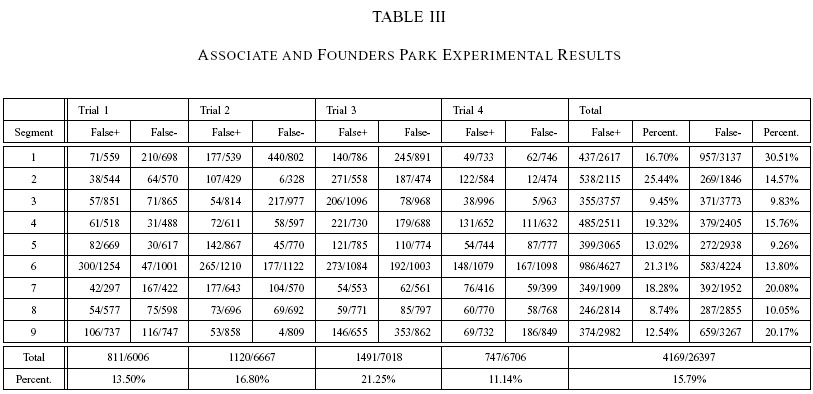
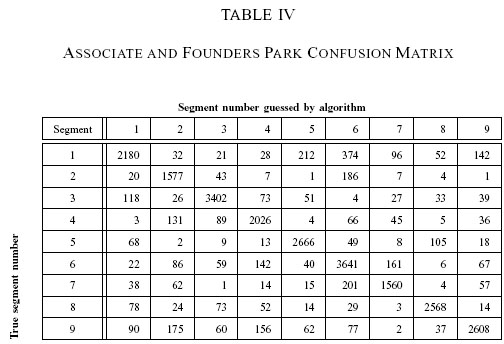
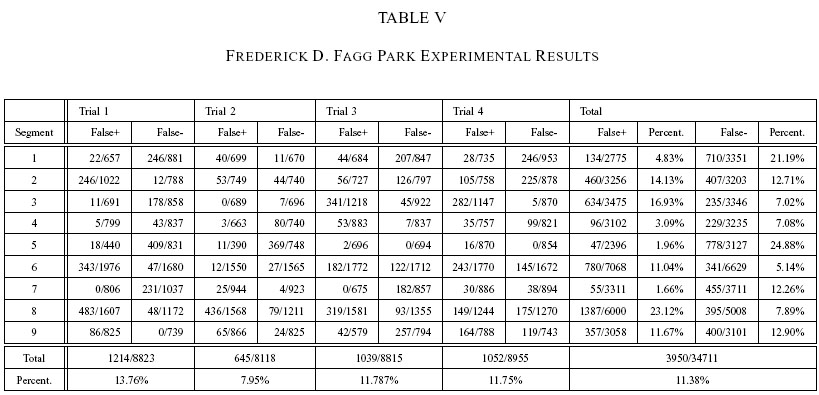
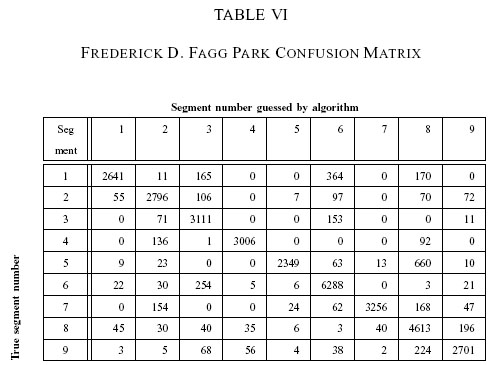
The result for each site is shown in Tables 1 to 6, in columnar and confusion matrix format. Table 7 and 8 will be explained below. For table 1, 3, 5 and 7, The
term "False +" or false positive for segment x means the percentage of incorrect
segment x guesses given that the correct answer is another segment,
while "False-" or false negative is the number of incorrect guesses given that the
correct answer is segment x.
The system is able to classify the ACB segments with an overall 87.96% correctness while AnF is marginally lower (84.21%). If we look at the challenges presented by the scenes
in the second site (dominated by vegetation) it is quite an
accomplishment to only lose less than 4 percent in performance with no
calibration done in moving from the first environment to the second.
Increase in length of segments also do not markedly affect the results
as FDF (86.38%), which is have the longest lengths among the
experiments are better than AnF. As a performance reference, when we
test the system with a set of data taken back-to-back with training
data, the classification rate are about 89 to 91 percent. On the
other hand, when lighting condition of a testing data are not included
in training, the error would triple to thirty to forty percent which
suggest that lighting coverage in the training phase is critical.
Ahmanson Center for Biological Science (ACB)
A video of a test run for Ahmanson Center for Biological Science
can be viewed here
Associate and Founders Park (AnF)
A video of a test run for Associate and Founders Park
can be viewed here
Frederick D. Fagg park (FDF)
A video of a test run for Frederick D. Fagg park
can be viewed here
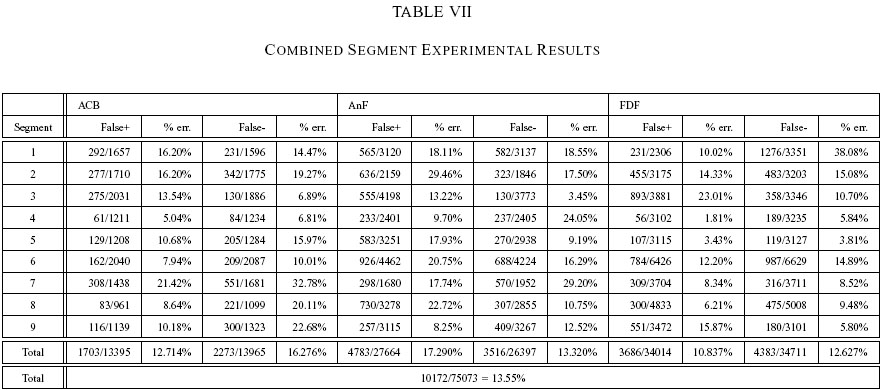
Combined Sites
As a way to gauge the system's scalability, we combine scenes from all
three sites and train it to classify twenty seven different
segments. We use the same procedure as well as training and testing
data (175,406 and 75,073 frames, respectively). The only difference is
in the neural-network classifier, the output layer now consists of
twenty-seven nodes. The number of the input and hidden nodes remains
the same. During training we print the confusion matrix periodically
to analyze the process and find that the network converges from
inter-site classification before going further and eliminate the
intra-site errors.
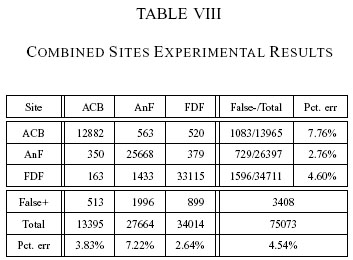
We organize the results into segment-level (Table 7) and site-level
(Table 8) statistics. For segment-level classification, the overall
success rate is 84.61%, not much worse than the previous three
experiments. Notice also that the success among the individual sites
changes as well. From the site-level confusion matrix (table 8), we
see that the system can reliably pin the scene to the correct site
(higher than 94 percent). This is encouraging because the classifier
can provide various levels of outputs. That is, when the system is
unsure about the actual segment location, it can at least rely on
being at the right site.
Model Comparisons
we also compared our model with three other models:
- Renniger and Malik [2004] use a set of texture descriptors as histogram entries
- Oliva and Torralba [2001] perform 2D Fourier Transform analysis (followed by PCA) in sub-region grid.
- Torralba et. al. [2003] use steerable wavelet pyramids
They are reported in VSS 2008 poster

Discussion
We have shown that the gist features succeed in classifying a large
set of images without the help of temporal filtering (one-shot
recognition), which reduce noise significantly [Torralba2003]. In
terms of robustness, the features are able to handle translational and
angular change. Because they are computed from large image
sub-regions, it takes a large translational shift to affect the
values. As for angular stability, the natural perturbation of a camera
carried through a bumpy road during training seems to aid the
demonstrated invariance. In addition, the gist features are also
invariant to scale because the majority of the scenes (background) are
stationary and the system is trained with all viewing distances. The
combined-sites experiment shows that the number of differentiable
scenes can be quite high. Twenty seven segments can make up a detailed
map of a large area. Lastly, the gist features achieve a solid
illumination invariance when trained with different lighting
conditions.
A drawback of the current system is that it cannot carry out partial
background matching for scenes in which large parts are occluded by
dynamic foreground objects. As mentioned earlier the videos are filmed
during off-peak hours when few people (or vehicles) are on the
road. Nevertheless, they can still create problems when moving too
close to the camera. In our system, these images can be taken out
using the motion cues from the not yet incorporated motion channel as
a preprocessing filter, detecting significant occlusion by
thresholding the sum of the motion channel feature maps [Itti04tip].
Furthermore, a wide-angle lens (with software distortion correction)
can help to see more of the background scenes and, in comparison,
decrease the size of the moving foreground objects.
Conclusion
The current gist model is able to provide high-level context
information (a segment within a site) from various large and difficult
outdoor environments despite using coarse features. We find that
scenes from differing segments contrast in a global manner and gist
automatically exploit them and thus reduce a need for detailed
calibration in which a robot has to rely on the ad-hoc knowledge of
the designer for reliable landmarks. And because the raw features can
be shared with the saliency model, the system can efficiently increase
localization resolution. It can use salient cues to create distinct
signature of individual scenes, finer point of reference, within
segment that may not be differentiable by gist alone. The salient cues
can even help guide localization for the area between segments which
we did not try to classify.
Copyright © 2000 by the University of
Southern California, iLab and Prof. Laurent Itti