
We present a vision-based
navigation and localization system using two biologically-inspired
scene understanding models which are studied from human visual
capabilities: (1) Gist model which
captures the holistic characteristics and layout of an image and (2)
Saliency model which emulates the visual attention of primates to
identify conspicuous regions in the image. Here the
localization
system utilizes the gist features and salient regions to
accurately localize the robot, while the navigation system uses the
salient regions to perform visual feedback control to direct its
heading and go to a user-provided goal location. We tested the system
on our robot, Beobot2.0, in an indoor and outdoor environment with a
route length of 36.67m (10,890 video frames) and 138.27m (28,971
frames), respectively. On average, the robot is able to drive within
3.68cm and 8.78cm (respectively) of the center of the lane.
Index Terms: Gist of a scene, saliency, scene recognition,
computational neuroscience, image classification, image statistics,
robot vision, saliency, robot navigation.


 C.-K. Chang*, C. Siagian*, L. Itti,
Mobile Robot Vision Navigation & Localization Using Gist and Saliency,
C.-K. Chang*, C. Siagian*, L. Itti,
Mobile Robot Vision Navigation & Localization Using Gist and Saliency,
In: Proc. IEEE/RSJ International
Conference on Intelligent Robots and Systems (IROS),
Oct 2010 (*equal authorship).
Ability to go to specific locations in one's environment in a timely manner in both indoor and outdoor environments is fundamental in creating a fully autonomous mobile robotic system. To do so, a robot not only has to be able to move about its environment, but it also has to identify its location. In the current state of robotic research, vision-based navigation and localization are usually dealt with separately. For the most part, available literature concentrates more on one but not the other. Researchers who work on vision localization manually control their robots to move about the environment. On the other hand, visual navigation is usually performed for a single predefined route, where robots do not have to decide on where to turn when encountering an intersection. There are also, however, road recognition systems that try to recognize the road's appearance as well as boundaries, instead of identifying landmarks. However, for these type of systems, the robot merely follows the road and keeps itself within its boundaries, not knowing where it will ultimately end up.
If a system has both localization and navigation, we can command it to go to any goal location in the environment by using the former to compute a route and the latter to execute movements. In addition, such an integrated system can internally share resources (visual features, for one) to make the overall system run more effectively. However, this also poses a challenging problem of integrating complex sub-systems.
We present a mobile robot vision system that both localizes and navigates by extending our previous work of Gist-Saliency localization. Instead of just navigating through a pre-specified path (like teach-and-replay [Chen 2009t-robotics]), the robot can execute movements through any desired routes in the environment (e.g., routes generated by a planner). On the other hand, unlike teach-and-replay, a stand-alone localization system allows the navigation system to not be overly sensitive to the temporal order of input images. We tested the system in both indoor and outdoor environments, each recorded multiple times to validate our approach.
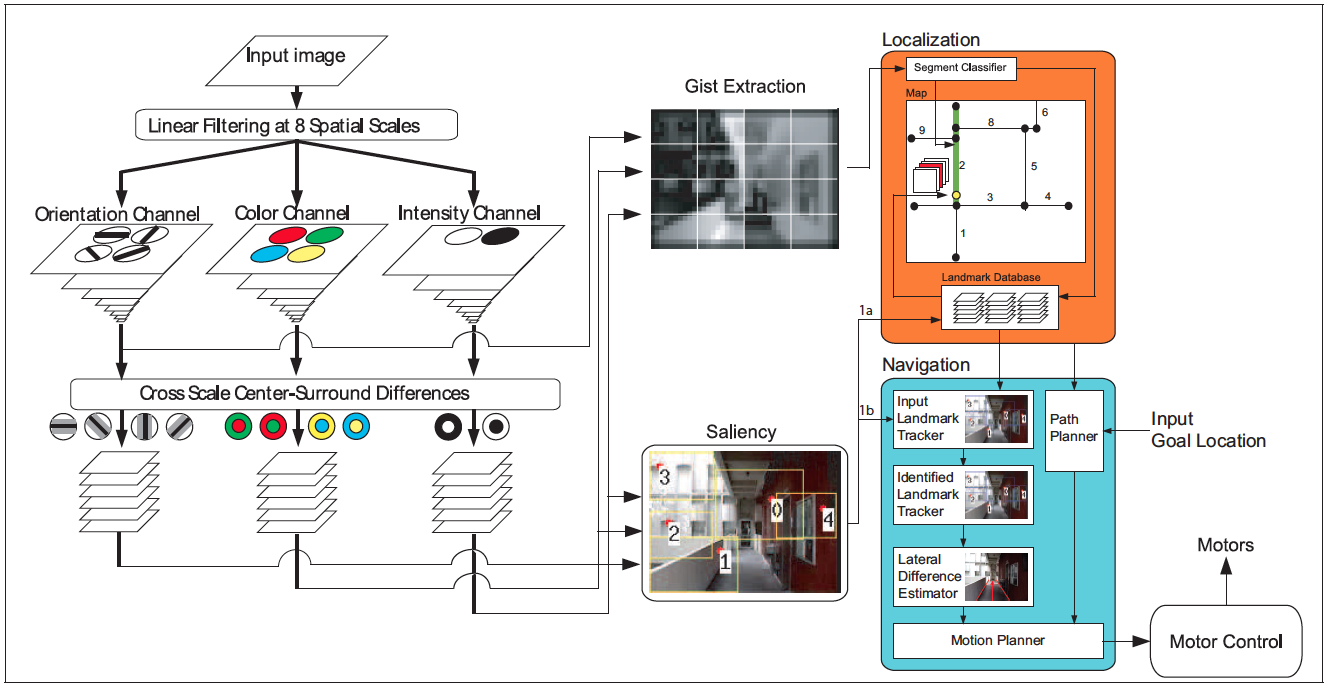
Our presented mobile robot vision navigation and localization system (illustrated in Figure 1) utilizes biologically inspired features: gist and salient regions of an image, obtained from a single straight-forward view camera. Both features are computed in parallel, utilizing shared raw Visual Cortex visual features from the color, intensity and orientation domain. In addition, the navigation and localization systems also run in parallel in the system.
Figure 1. Model of Human Vision with Gist and Saliency.
The main mechanism of this landmark-based navigation system is using the canonical image coordinate of the recognized landmark to keep the robot as close as possible to the correct path for the location. The canonical image coordinate is obtained during the training process, where the robot is driven by human. However, since we have a localization system, when the robot comes at an intersection, it can make the right decision of which direction to take to go to the current goal location.
One important point to make is that in order to utilize a complex algorithm such as vision-based localization, we track the landmarks during the process. By tracking them, when the regions are positively identified at a later time (usually database search finishes in the order of seconds), we can still pinpoint their image coordinate for navigation. The navigation system calculates the coordinate difference between the tracked region and the matched database region as a feedback to the motor controller.
Copyright © 2000 by the University of Southern California, iLab and Prof. Laurent Itti