
We present a mobile robot navigation system guided by a novel
vision-based road recognition approach. The system represents the road
as a set of lines extrapolated from the detected image contour
segments. These lines enable the robot to maintain its heading by
centering the vanishing point in its field of view, and to correct the
long term drift from its original lateral position. We integrate
odometry and our visual road recognition system into a grid-based
local map that estimates the robot pose as well as its surroundings to
generate a movement path. Our road recognition system is able to
estimate the road center on a standard dataset with 25,076 images to
within 11.42 cm (with respect to roads at least 3 m wide). It
outperforms three other state-of-the-art systems. In addition, we
extensively test our navigation system in four busy college campus
environments using a wheeled robot. Our tests cover more than 5 km of
autonomous driving without failure. This demonstrates robustness of
the proposed approach against challenges that include occlusion by
pedestrians, non-standard complex road markings and shapes, shadows,
and miscellaneous obstacle objects.
Index Terms: visual road recognition, contour, robot vision, robot navigation.


 C. Siagian*, C.-K. Chang*, L. Itti,
Mobile Robot Navigation System in Outdoor Pedestrian Environment Using Vision-Based Road Recognition,
C. Siagian*, C.-K. Chang*, L. Itti,
Mobile Robot Navigation System in Outdoor Pedestrian Environment Using Vision-Based Road Recognition,
In: Proc. IEEE International Conference on Robotics and Automation (ICRA),
Oct 2010 (*equal authorship).
Mobile robot navigation is a critical component in creating truly autonomous systems. In the past decade, there has been tremendous progress, particularly indoors, as well as on the street for autonomous cars. However, such is not the case for autonomous navigation in unconstrained pedestrian environments for applications such as service robots. Pedestrian environments pose a different challenge than indoors because they are more open with far fewer surrounding walls, which drastically reduces the effectiveness of proximity sensors to direct the robot. At the same time, pedestrian roads are much less regulated than the ones driven on by cars, which provide well specified markings and boundaries.
Our contributions start by presenting a novel vision-based general road recognition algorithm by detecting the Vanishing Point in the image using long and robust contour segments. We show that this approach is more robust than previous algorithms that relied on smaller and often noisier edgels. We then flexibly model the road using a group of lines, instead of the rigid triangular road image shape. We demonstrate how this yields fewer mistakes when the road shape is non- trivial (e.g., a plaza on a university campus).
In addition, we design and implement an autonomous navigation framework that fuses the visual road recognition system with odometry information to refine the estimated road heading. Taken together, we find that these new components produce a system that outperforms the state of the art. First, we are able to produce more accurate estimates of the road center than three benchmark algorithms on a standard dataset (25,076 images). Second, implementing the complete system in real-time on a mobile robot, we demonstrate fully autonomous navigation over more than 5 km of different routes on a busy college campus. We believe that our study is to date the largest-scale successful demonstration of an autonomous road finding algorithm in a complex campus environment.
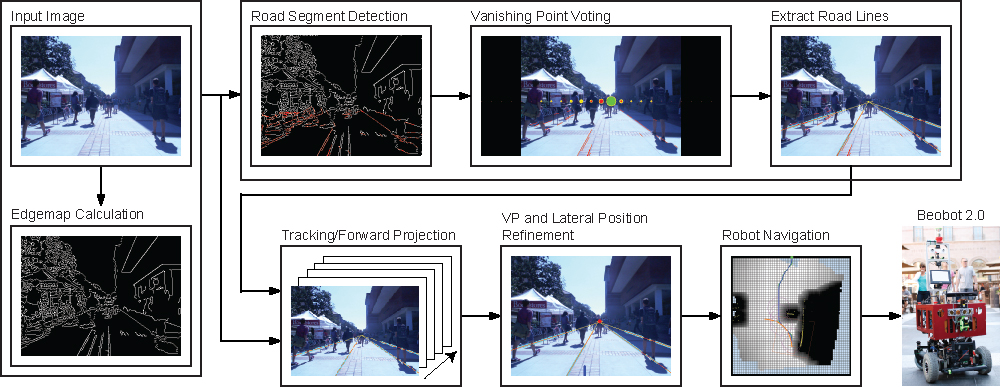
Figure 1.
Diagram of visual road recognition algorithm.
The road recognition system first takes the input image and performs Canny edge detection to create an edge map. From here there are two ways to recognize the road. One is through a full recognition process (the top pipeline in the above figure 1), where the system uses detected segments in the edgemap to vote for the most likely VP and to extract the road lines. This process can take a sizable time, exceeding the input frame period. The bottom pipeline, on the other hand, is much faster because it uses the available road lines and tracks them. In both pipelines, the system then utilizes the updated lines to produce an estimated road heading and lateral position of the robot. The latter measures how far the robot has deviated from the original lateral position, which is important, e.g., if one wants the robot to stay in the middle of the road. In the system, tracking accomplishes two purposes. One is to update previously discovered road lines. The second is to project forward the resulting new road lines through the incoming unprocessed frames accumulated while the recognition process is computing. The results then passed to the navigation system, which proceeds to compute a motor command to be executed by our robot, Beobot 2.0.
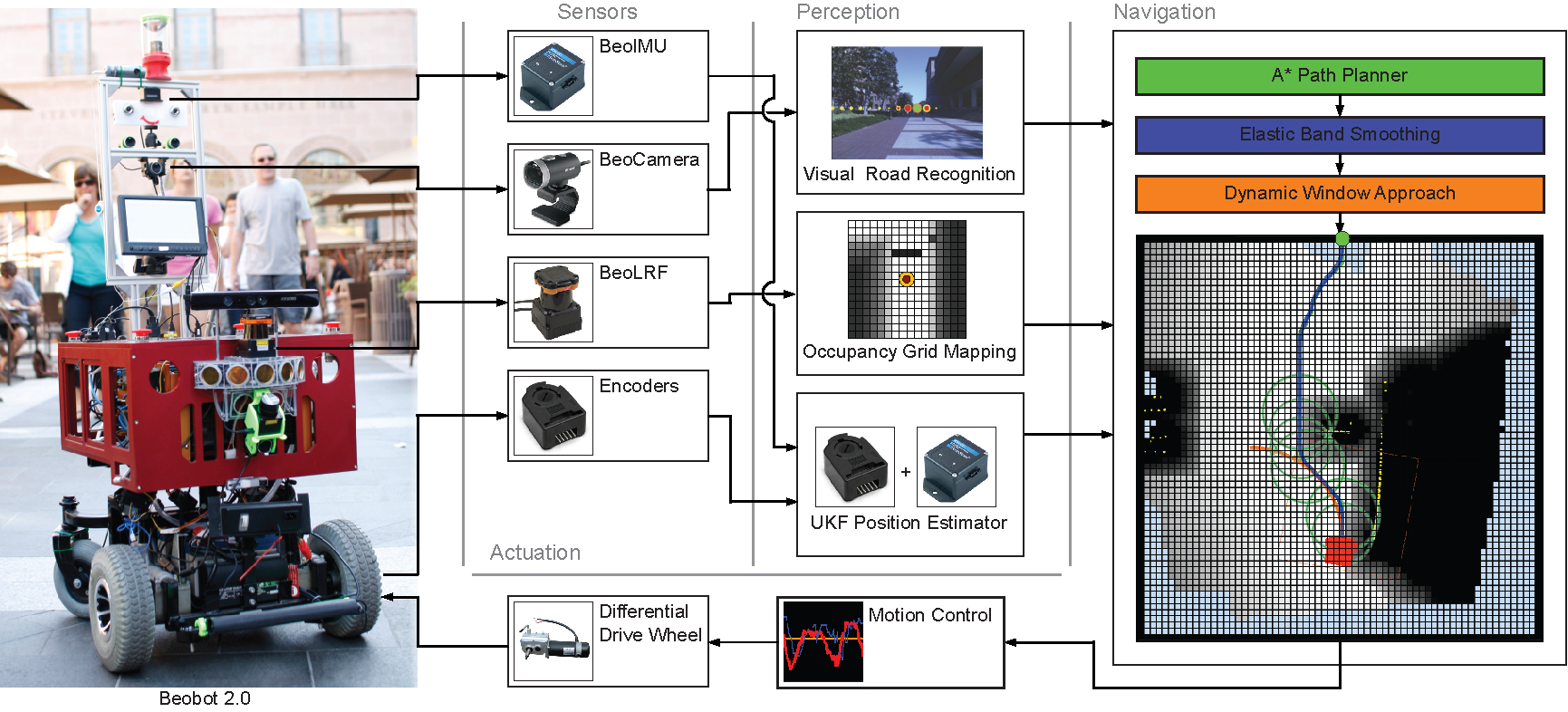
Figure. 2. Beobot 2.0 autonomous navigation system.
The overall navigation system, as illustrated in the above figure 2, takes in the visual road recognition output, as well as Laser Range Finder (LRF), and odometry (from IMU and encoders) values. The LRF is particularly useful for obstacle detection and avoidance, while the IMU and wheel encoder data supplement the visual road finding algorithm in difficult conditions (e.g, sun shining into the camera). The information is then fused to create the robot local surrounding map, while estimating the road and robot heading.
The local map is a 64 by 64 grid occupancy map, where each grid cell spans a 15cm by 15cm spatial area. The robot location in the map is displayed as a red rectangle and is located at the horizontal center and three quarters down vertically to increase front-of-robot coverage. In addition, there is a layer of grid surrounding the map to represent goal locations outside of it. The figure shows the goal to be straight ahead, which, by convention, is the direction of the road. To reach the goal the system computes a path using the A*, deforms it maximally avoid obstacles using the elastic band algorithm, and generates motion command that account for robot shape and dynamics using Dynamic Window Approach (DWA).
Copyright © 2000 by the University of Southern California, iLab and Prof. Laurent Itti