Ali Borji
iLab, Hedco Neuroscience Building, USC
Los Angeles, California
Research
Human vs. computer in scene and object recognition
Several decades of research in computer and primate vision
have resulted in many models (some specialized for
one problem, others more general) and invaluable experimental
data. Here, to help focus research efforts onto the
hardest unsolved problems, and bridge computer and human
vision, we define a battery of 5 tests that measure the
gap between human and machine performances in several
dimensions (generalization across scene categories, generalization
from images to edge maps and line drawings, invariance
to rotation and scaling, local/global information
with jumbled images, and object recognition performance).
We measure model accuracy and the correlation between
model and human error patterns. Experimenting over 7
datasets, where human data is available, and gauging 14
well-established models, we find that none fully resembles
humans in all aspects, and we learn from each test which
models and features are more promising in approaching humans
in the tested dimension. Across all tests, we find that
models based on local edge histograms consistently resemble
humans more, while several scene statistics or "gist"
models do perform well with both scenes and objects. While
computer vision has long been inspired by human vision, we
believe systematic efforts, such as this, will help better identify
shortcomings of models and find new paths forward.
Gaze direction modulates eye movements in freeviewing
Gaze direction provides an important and ubiquitous communication channel in daily behavior and social interaction of
humans and some animals. While several studies have addressed gaze direction in synthesized simple scenes, few have
examined how it can bias observer attention and how it might interact with early saliency during free viewing of
natural scenes. Experiment 1 used a controlled, staged setting in which an actor was asked to look at two different
objects in turn, yielding two images that only differed by the actor's gaze direction, to causally assess the effects
of actor gaze direction. Over all scenes, the median probability of following an actor's gaze direction was higher
than the median probability of looking towards the single most salient location (0.22 vs. 0.10; sign test,
p=3.223e-06), and higher than chance (both uniform, 0.02; p=6.750e-17, and Naive Bayes, 0.06;
p=6.171e-10). Experiment 2 confirmed these findings over a larger set of unconstrained scenes collected from the web
and containing people looking at objects and/or other people. To further compare the strength of saliency vs.\ gaze
direction cues, we computed gaze maps by drawing a cone in the direction of gaze of the actors present in the images.
Gaze maps predicted observers' fixation locations significantly above chance, although below saliency (AUC; gaze map
vs. saliency map 0.612 vs. 0.797 in exp 1 and 0.625 vs. 0.789 in exp 2). Finally, to gauge the relative
importance of actor face and eye directions in guiding observer's fixations, in experiment 3, observers were asked to
guess the gaze direction from only an actor's face region (with the rest of the scene masked), in two conditions:
actor eyes visible or masked. Median probability of guessing the true gaze direction within +/- 9 degrees was
significantly higher when eyes were visible (0.2 vs. 0.13; sign test, p=5.76e-15), suggesting that the eyes
contribute significantly to gaze estimation, in addition to face region. Our results highlight that gaze direction
is a strong attentional cue in guiding eye movements, complementing low-level saliency cues, and derived from both
face and eyes of actors in the scene. Thus gaze direction should be considered in constructing more predictive visual
attention models in the future.
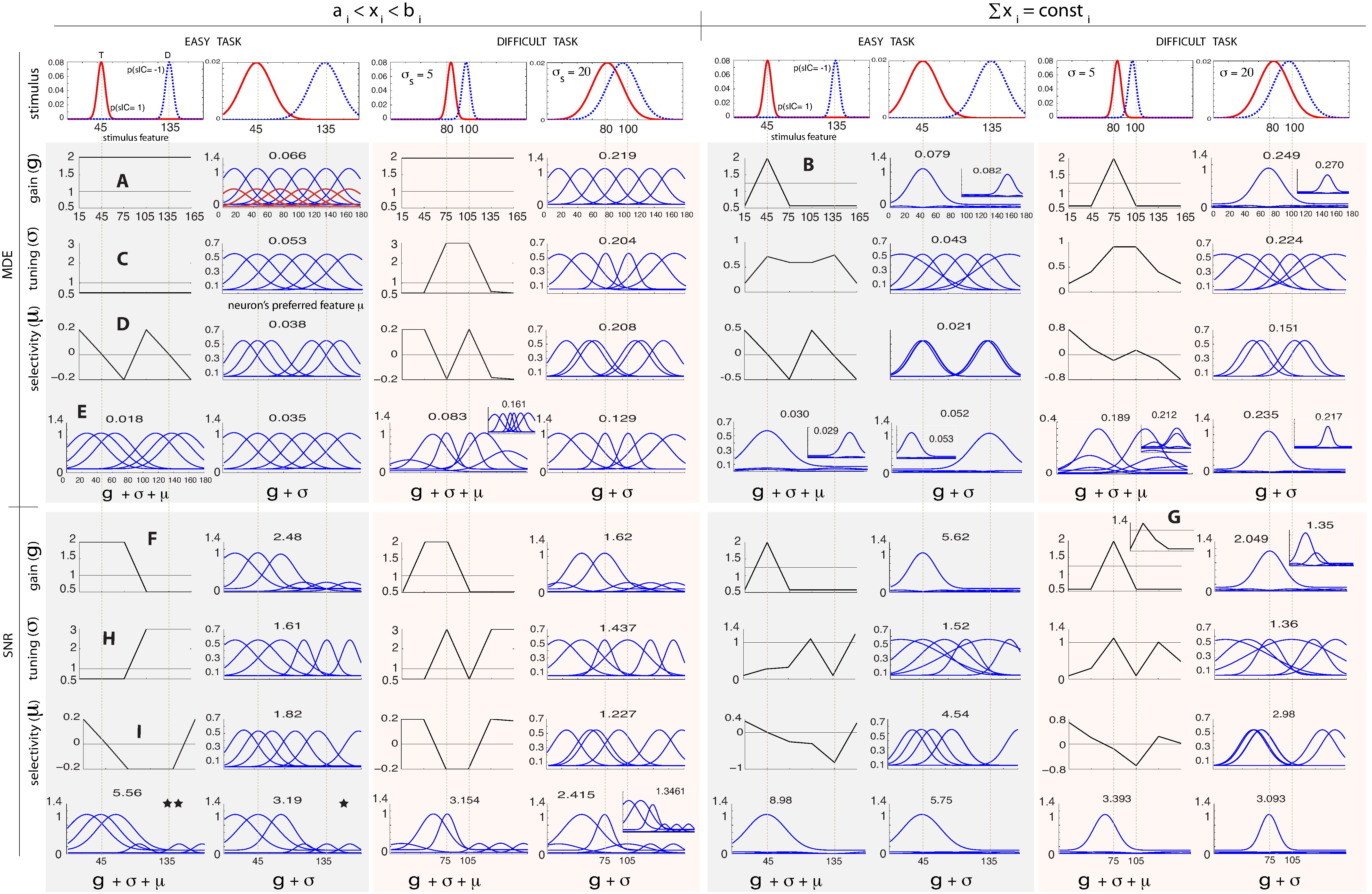
Optimal Attentional Modulation of a Neural Population
Top-down attention has often been separately studied in the contexts
of either optimal population coding or biasing of visual search.
Yet, both are intimately linked, as they entail optimally modulating
sensory variables in neural populations according to top-down
goals. Designing experiments to probe top-down attentional modulation
is difficult because non-linear population dynamics are hard to
predict in the absence of a concise theoretical framework. Here, we
describe a unified framework that encompasses both
contexts. Our work sheds light onto the ongoing debate on whether
attention modulates neural response gain, tuning width, and/or
preferred feature. We evaluate the framework by conducting
simulations for two tasks: 1) classification (discrimination) of two
stimuli s_a and s_b and 2) searching for a target T among
distractors D. Results demonstrate that all of gain, tuning, and
preferred feature modulation happen to different extents, depending
on stimulus conditions and task demands. The theoretical
analysis shows that task difficulty (linked to difference Δ
between s_a and s_b, or T and D) is a crucial factor in
optimal modulation, with different effects in discrimination vs.
search. Further, our framework allows us to quantify the relative
utility of neural parameters. In easy tasks (when Δ is large
compared to the density of the neural population), modulating gains
and preferred features is sufficient to yield nearly optimal
performance; however, in difficult tasks (smaller Δ),
modulating tuning width becomes necessary to improve
performance. This suggests that the conflicting reports from
different experimental studies may be due to differences in tasks
and in their difficulties. We further propose future electrophysiology experiments
to observe different types of attentional modulation in a same neuron.
In a very influential yet anecdotal illustration, Yarbus suggested
that human eye movement patterns are modulated top-down by different
task demands. While the hypothesis that it is possible to decode
the observer's task from eye movements has received some support
(e.g., Iqbal & Bailey (2004); Henderson et al. (2013)), Greene et al. (2012)
argued against it by reporting a failure. In this study, we perform a more
systematic investigation of this problem, probing a larger number of
experimental factors than previously. Our main goal is to determine
the informativeness of eye movements for task and mental state
decoding. We perform two experiments. In the first experiment, we
re-analyze the data from a previous study by Greene et al. (2012) and
contrary to their conclusion, we report that it is possible
to decode the observer's task from aggregate eye movement features slightly but
significantly above chance, using a Boosting classifier (34.12% correct vs. 25% chance-level; binomial test, p = 1.07e-04). In the
second experiment, we repeat and extend Yarbus' original experiment
by collecting eye movements of 21 observers viewing 15 natural
scenes (including Yarbus' scene) under Yarbus' seven questions. We show
that task decoding is possible, also moderately but significantly
above chance (24.21% vs. 14.29% chance-level; binomial test, p = 2.45e-06). We
thus conclude that Yarbus' idea is supported by our data and
continues to be an inspiration for future computational and
experimental eye movement research. From a broader perspective, we
discuss techniques, features, limitations, societal and
technological impacts, and future directions in task decoding from
eye movements.
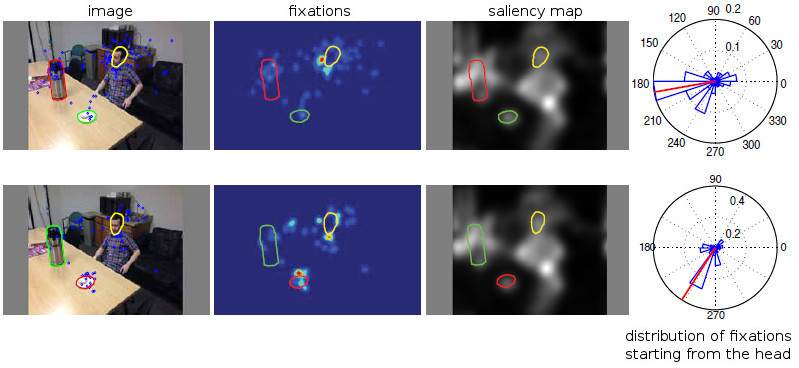
Objects do not predict fixations better than early saliency; Reanalysis of Einhauser et al.'s data
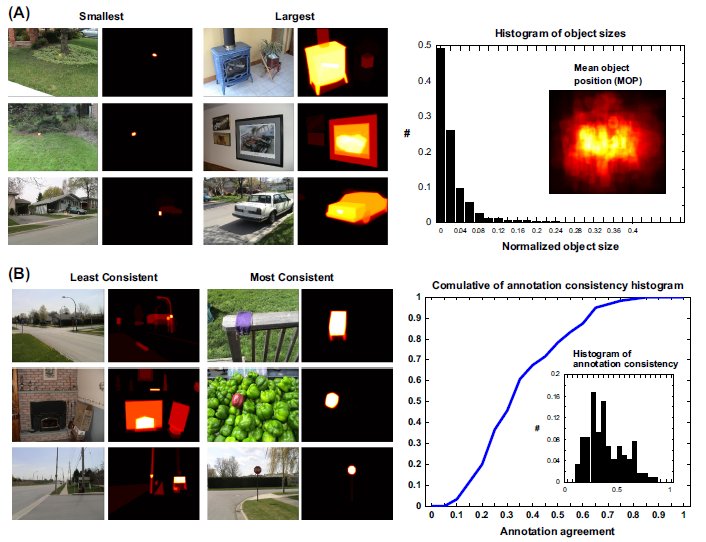
Einhauser, Spain, and Perona (2008) explored an
alternative hypothesis to saliency maps (i.e., spatial
image outliers) and claimed that "objects predict
fixations better than early saliency." To test their
hypothesis, they measured eye movements of human
observers while they inspected 93 photographs of
common natural scenes (Uncommon Places dataset by
Shore, Tillman, & Schmidt-Wulen 2004; Supplement
Figure S4). Subjects were asked to observe an image and,
immediately afterwards, to name objects they saw
(remembered). Einhauser et al. showed that a map
made of manually drawn object regions, each object
weighted by its recall frequency, predicts fixations in
individual images better than early saliency. Due to
important implications of this hypothesis, we investigate
it further. The core of our analysis is explained here.
Please refer to the Supplement for details.
What/Where to Look Next? Modeling Top-down Visual Attention in Complex Interactive Environments
Several visual attention models have been proposed for describing eye movements over simple stimuli
and tasks such as free viewing or visual search. Yet to date, there
exists no computational framework that can reliably mimic human
gaze behavior in more complex environments and tasks such as urban
driving. Additionally, benchmark datasets, scoring techniques, and
top-down model architectures are not yet well understood.
In this study, we describe new task-dependent approaches for modeling top-down overt visual
attention based on graphical models for probabilistic inference and reasoning. We
describe a Dynamic Bayesian Network (DBN) that infers probability
distributions over attended objects and spatial locations
directly from observed data. Probabilistic inference in our model is performed
over object-related functions which are fed from manual
annotations of objects in video scenes or by state-of-
the-art object detection/recognition algorithms.
Evaluating over ~3 hours (appx. 315,000 eye fixations and
12,600 saccades) of observers playing 3 video games
(time-scheduling, driving, and flight combat), we show that our
approach is significantly more predictive of eye fixations compared
to: (1) simpler classifier-based models also developed here that map
a signature of a scene (multi-modal information from gist, bottom-up saliency, physical actions, and events) to eye positions, (2) 14
state-of-the-art bottom-up saliency models, and (3) brute-force
algorithms such as mean eye position. Our results show that the proposed model is more effective in employing and reasoning over
spatio-temporal visual data compared with the state-of-the-art.
Eye tracking has become the de facto standard measure of
visual attention in tasks that range from free viewing to complex
daily activities. In particular, saliency models are often evaluated
by their ability to predict human gaze patterns. However, fixations
are not only influenced by bottom-up saliency (computed by the
models), but also by many top-down factors. Thus, comparing
bottom-up saliency maps to eye fixations is challenging and has
required that one tries to minimize top-down influences, for example
by focusing on early fixations on a stimulus. Here we propose two
complementary procedures to evaluate visual saliency. We seek
whether humans have explicit and conscious access to the saliency
computations believed to contribute to guiding attention and eye
movements. In the first experiment, 70 observers were asked to
choose which object stands out the most based on its low-level
features in 100 images each containing only two objects. Using
several state-of-the-art bottom-up visual saliency models that
measure local and global spatial image outliers, we show that
maximum saliency inside the selected object is significantly higher
than inside the non-selected object and the background. Thus spatial
outliers are a predictor of human judgments. Performance of this
predictor is boosted by including object size as an additional
feature. In the second experiment, observers were asked to draw a
polygon circumscribing the most salient object in cluttered
scenes. For each of 120 images, we show that a map built from
annotations of 70 observers explains eye fixations of another 20
observers freely viewing the images, significantly above chance
(dataset by Bruce & Tsotsos 2009; shuffled AUC score 0.62 +/- 0.07,
chance 0.50, t-test p < 0.05). We conclude that fixations agree
with saliency judgments, and classic bottom-up saliency models explain both. We further find that computational models specifically
designed for fixation prediction slightly outperform models
designed for salient object detection over both types of data (i.e.,
fixations and objects).
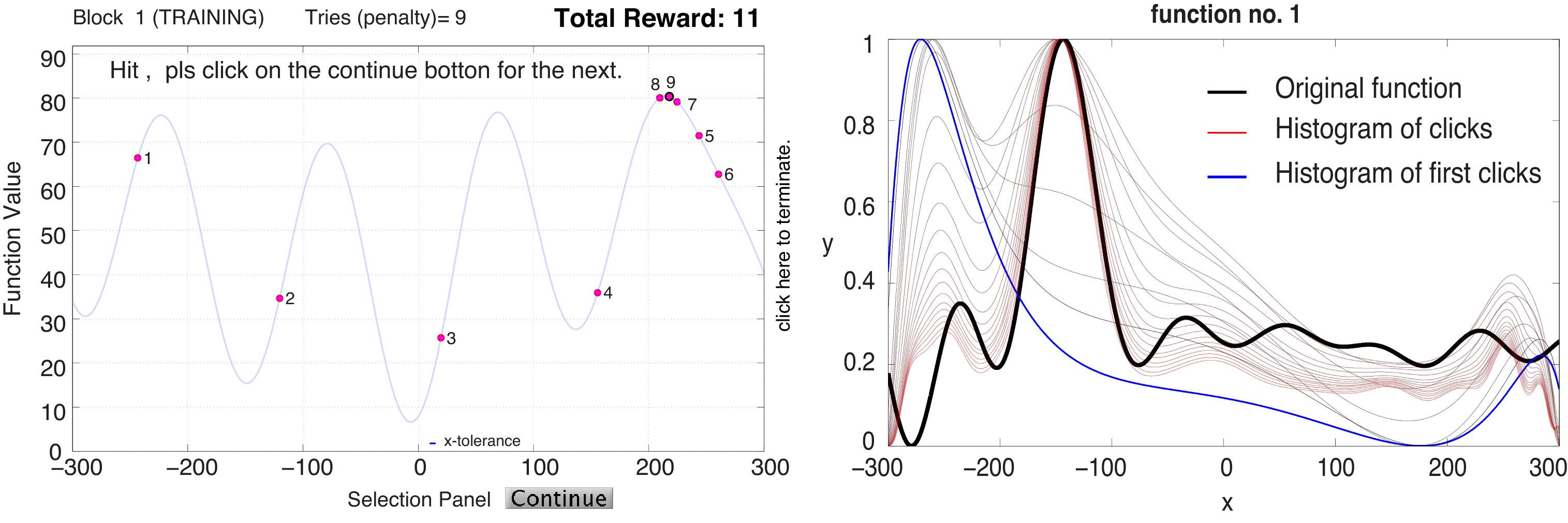
Many real-world problems have complicated objective functions. To optimize
such functions, humans utilize sophisticated sequential decision-making strategies.
Many optimization algorithms have also been developed for this same purpose,
but how do they compare to humans in terms of both performance and behavior?
We try to unravel the general underlying algorithm people may be using
while searching for the maximum of an invisible 1D function. Subjects click on
a blank screen and are shown the ordinate of the function at each clicked abscissa
location. Their task is to find the function’s maximum in as few clicks as possible.
Subjects win if they get close enough to the maximum location. Analysis over
23 non-maths undergraduates, optimizing 25 functions from different families,
shows that humans outperform 24 well-known optimization algorithms. Bayesian
Optimization based on Gaussian Processes, which exploit all the x values tried
and all the f(x) values obtained so far to pick the next x, predicts human performance
and searched locations better. In 6 follow-up controlled experiments
over 76 subjects, covering interpolation, extrapolation, and optimization tasks, we
further confirm that Gaussian Processes provide a general and unified theoretical
account to explain passive and active function learning and search in humans.
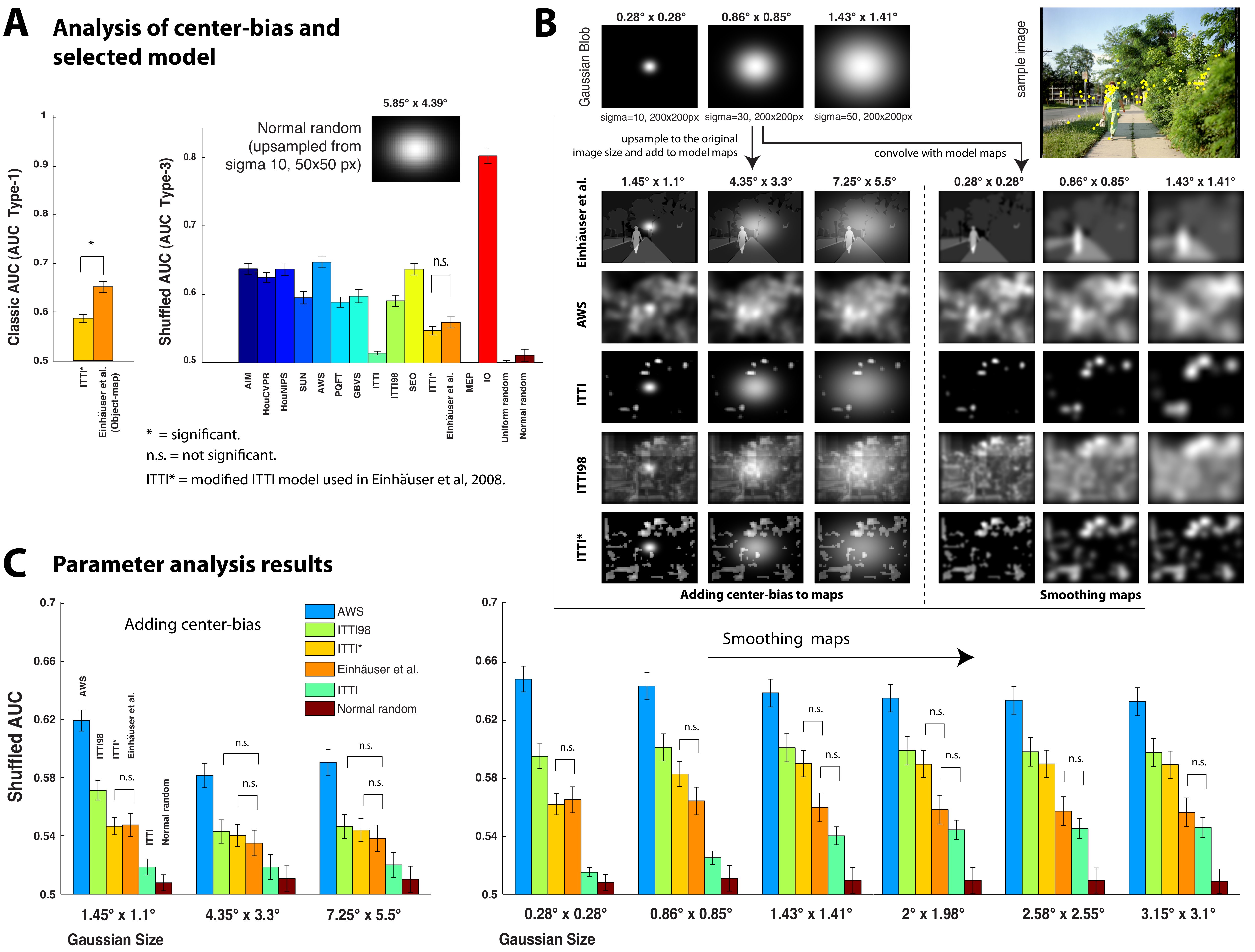
Benchmarking saliency (fixation prediciton and salient object detection) models
Visual attention is a process that enables biological
and machine vision systems to select the most relevant regions
from a scene. Relevance is determined by two components:
1) top-down factors driven by task and 2) bottom-up factors
that highlight image regions that are different from their surroundings.
The latter are often referred to as “visual saliency”.
Modeling bottom-up visual saliency has been the subject of
numerous research efforts during the past 20 years, with many
successful applications in computer vision and robotics. Available
models have been tested with different datasets (e.g., synthetic
psychological search arrays, natural images or videos) using
different evaluation scores (e.g., search slopes, comparison to
human eye tracking) and parameter settings. This has made
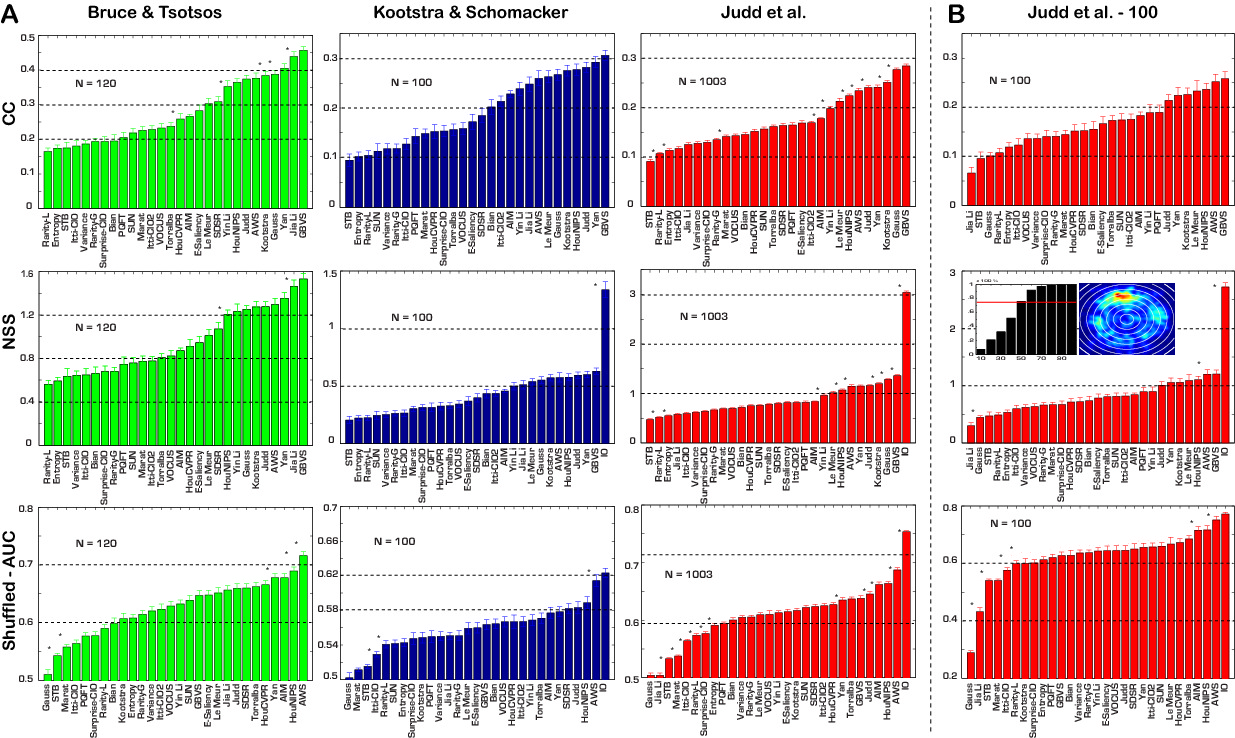
direct comparison of models difficult. Here we perform an
exhaustive comparison of 35 state-of-the-art saliency models over
54 challenging synthetic patterns, 3 natural image datasets, and
2 video datasets, using 3 evaluation scores. We find that although
model rankings vary, some models consistently perform better.
Analysis of datasets reveals that existing datasets are highly
center-biased, which influences some of the evaluation scores.
Computational complexity analysis shows that some models are
very fast, yet yield competitive eye movement prediction accuracy.
Different models often have common easy/difficult stimuli.
Furthermore, several concerns in visual saliency modeling, eye
movement datasets, and evaluation scores are discussed and
insights for future work are provided. Our study allows one to
assess the state-of-the-art, helps organizing this rapidly growing
field, and sets a unified comparison framework for gauging future
efforts, similar to the PASCAL VOC challenge in the object
recognition and detection domains.
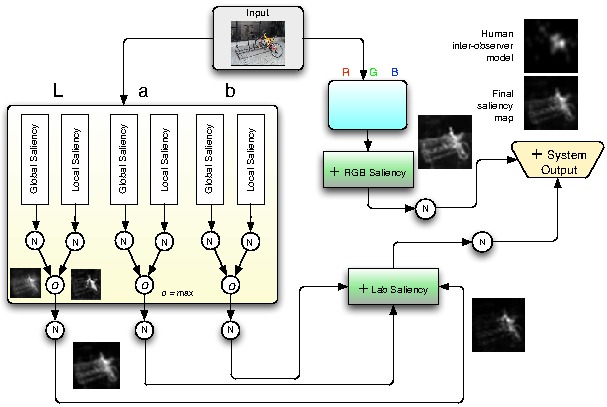
Modeling Bottom-up saliency and fixation prediction
We introduce a saliency model based on two key ideas.
The first one is considering local and global image patch
rarities as two complementary processes. The second one
is based on our observation that for different images, one
of the RGB and Lab color spaces outperforms the other in
saliency detection. We propose a framework that measures
patch rarities in each color space and combines them in
a final map. For each color channel, first, the input image
is partitioned into non-overlapping patches and then
each patch is represented by a vector of coefficients that
linearly reconstruct it from a learned dictionary of patches
from natural scenes. Next, two measures of saliency (Local
and Global) are calculated and fused to indicate saliency
of each patch. Local saliency is distinctiveness of a patch
from its surrounding patches. Global saliency is the inverse
of a patch’s probability of happening over the entire image.
The final saliency map is built by normalizing and fusing
local and global saliency maps of all channels from both
color systems. Extensive evaluation over four benchmark
eye-tracking datasets shows the significant advantage of our
approach over 10 state-of-the-art saliency models.
Probabilistic Learning of Task-Specific Visual Attention
Despite a considerable amount of previous work on bottom-up saliency
modeling for predicting human fixations over static and dynamic
stimuli, few studies have thus far attempted to model top-down and
task-driven influences of visual attention. Here, taking advantage
of the sequential nature of real-world tasks, we propose a unified
Bayesian approach for modeling task-driven visual attention. Several
sources of information, including global context of a scene,
previous attended locations, and previous motor actions, are
integrated over time to predict the next attended location.
Recording eye movements while subjects engage in 5 contemporary 2D
and 3D video games, as modest counterparts of everyday tasks, we
show that our approach is able to predict human attention and gaze
better than the state-of-the-art, with a large margin (about 15%
increase in prediction accuracy). The advantage of our approach is
that it is automatic and applicable to arbitrary visual tasks.
An Object-based Bayesian Framework for Top-down Visual Attention
We introduce a new task-independent framework to model top-down overt visual
attention based on graphical models for probabilistic inference and reasoning. We
describe a Dynamic Bayesian Network (DBN) that infers probability
distributions over attended objects and spatial locations
directly from observed data. Probabilistic inference in our model is performed over object-related functions which are
fed from manual annotations of objects in video scenes or by state-of-the-art object detection models.
Evaluating over $\sim$3 hours (appx. $315,000$ eye fixations and
$12,600$ saccades) of observers playing 3 video games
(time-scheduling, driving, and flight combat), we show that our
approach is significantly more predictive of eye fixations compared
to: 1) simpler classifier-based models also developed here that map
a signature of a scene (multi-modal information from gist, bottom-up saliency, physical actions, and events) to eye positions, 2) 14
state-of-the-art bottom-up saliency models, and 3) brute-force
algorithms such as mean eye position. Our results show that the proposed model is more effective in employing and reasoning over
spatio-temporal visual data.
Saliency-based Object Tracking. Tracking the main character for predicting eye movements
At the University of Bonn, we (Me and Dr. Frintrop) are applying visual attention for efficint object tracking.
A major problem with previous object tracking
approaches is adapting object representations depending on scene
context to account for changes in illumination, coloring, scaling,
rotation, etc. Our work is based on Frintrop's earlier approach for object tracking using particle
filters and features known to be extracted in the early visual
areas of the human brain. To adapt the previous approach for
background changes, we first derive some clusters from a train
sequence of frames and the object descriptors or representations
for those clusters. Next, for each frame of a separate test
sequence, its nearest background cluster is determined and
then the corresponding descriptor of that cluster is used for
object detection in this frame.
Both biological and machine vision systems have to process enormous amounts of visual information they
receive at any given time. Attentional selection provides an efficient solution to this information overload
problem by proposing a small set of scene regions to higher level and more computationally intensive
processes; like scene interpretation, object recognition, decision making, etc.
While bottom-up attention is solely determined by the image-based low-level cues, top-down attention on the other hand is influenced by task demands, prior knowledge of the
target and the scene, emotions, expectations, etc.The main concern in top-down att. is how to select the relevant information, since relevancy
depends on the tasks and the goals. In my research I have proposed approaches for consider task relevancy of visual information and to extract objects or spatial regions which help the agent to discover its state faster for decision making.
These approaches are based on reinforcement learning (to be precise, U-TREE) for action selection and attention control. The main idea is to learn visual attention while shaping representations, which happens in U-Tree
when discretizing aliased states.
Visual selection could be spatial or object-based. The first solution is motivated by human eye saccades and the second one selects objects as units of attention. To attend and recognize an object
in a natural cluttered scene, we have biased a bottom attention model (known as aliency-based model) for detection potential areas containing that object in a scene. Object recognition is then
limited to these areas. For detailed information, pls. refer to my papers listed in publications page.
There is a state of the art theory of object recognition in feedforward path of the visual ventral stream called HMAX
We have used the features proposed by this model for handwritten recognition and results compete with the best
tailored appraoches for this problem in the literature. We then analysed invariancy of two different feature sets of this model over the same problem
in a variaty of cases. In future, I am very interested to work on this model and see how recent electrophiological findings in ventral stream could help
to improve its performance.
Optimization has always been interesting and yet a challenging problem. Several biology inspired optimization algorithms such as Genetic Algorithms,
Ant Colony Optimization (ACO)and Particle Swarm Optimization (PSO) have previously
been proposed by researchers. Recent approaches in numerical optimization have
shifted to motivate from complex human social behaviors. In our research in this domain, we proposed a new optimization
algorithm, namely parliamentary optimization algorithm (POA) by
studying the competitive and collaborative behaviors of political parties in a parliament.
Experimental results reveal that our proposed approach is superior to PSO approach over
some benchmark multidimensional functions.
A biologically-inspired model of visual attention
known as basic saliency model is biased for object detection.
It is possible to make this model faster by inhibiting
computation of features or scales, which are less important
for detection of an object. To this end, we revise this model
by implementing a new scale-wise surround inhibition. Each
feature channel and scale is associated with a weight and
a processing cost. Then a global optimization algorithm is
used to find a weight vector with maximum detection rate
and minimum processing cost. This allows achieving maximum
object detection rate for real time tasks when maximum
processing time is limited. A heuristic is also proposed for
learning top-down spatial attention control to further limit
the saliency computation. Comparing over five objects, our
approach has 85.4 and 92.2% average detection rates with and
without cost, respectively, which are above 80% of the basic
saliency model. Our approach has 33.3 average processing
cost compared with 52 processing cost of the basic model.
We achieved lower average hit numbers compared with NVT
but slightly higher than VOCUS attentional systems.
Faces are complex and important visual stimuli for humans and are
subject to many psychophysical and computational studies. A new parametric
method for generating synthetic faces is proposed in this study. Two separate
programs, one in Delphi 2005 programming environment and another in
MATLAB is developed to sample real faces and generating synthetic faces
respectively. The user can choose to utilize default configurations or to
customize specific configurations to generate a set of synthetic faces. Headshape
and inner-hairline is sampled in a polar coordinate frame, located at the
center of line connecting two eyes at 16 and 9 equ-angular positions. Three
separate frames are placed at the left eyes center, nose tip and lips to sample
them with 20, 30 and 44 angular points respectively. Eyebrows are sampled
with 8 points in eye coordinate systems. Augmenting vectors representing these
features and their distance from the origin generates a vector of size 95. For
synthesized face, intermediate points are generated using spline curves and the
whole image is then band pass filtered. Two experiments are designed to show
that the set of generated synthetic faces match very well with their equivalent
real faces.
Zahra Basseda, Ali Borji, Behnaz Esmaeili, Asiyeh Zadbood, "Evaluating Temporal Dynamics of Different Facial Information in Face Perception," ECVP 2007, PERCEPTION, vol 36, pp 144.
Fast Hand Gesture Recognition based on Saliency Maps
In this research, we propose a fast algorithm for
gesture recognition based on the saliency maps of visual
attention. A tuned saliency-based model of visual attention is
used to find potential hand regions in video frames. To obtain
the overall movement of the hand, saliency maps of the
differences of consecutive video frames are overlaid. An
improved Characteristic Loci feature extraction method is
introduced and used to code obtained hand movement.
Finally, the extracted feature vector is used for training SVMs
to classify the gestures. The proposed method along a handeye
coordination model is used to play a robotic marionette
and an approval/rejection phase is used to interactively
correct the robotic marionette�s behavior.